資料庫 - 新手做 Data Migration 資料遷移
Preface
資料搬遷,在現代軟體服務當中屬於較為常見的一種需求
不論是單純的機器之間的搬資料抑或者是因應商業邏輯而需要做的資料搬遷等等
都是屬於 Data Migration
Introduction to Data Migration
雖然統稱 Data Migration 但實際上可以下分以下幾種
有的時候你只需要進行一種,有時候是多種的組合
Schema Migration
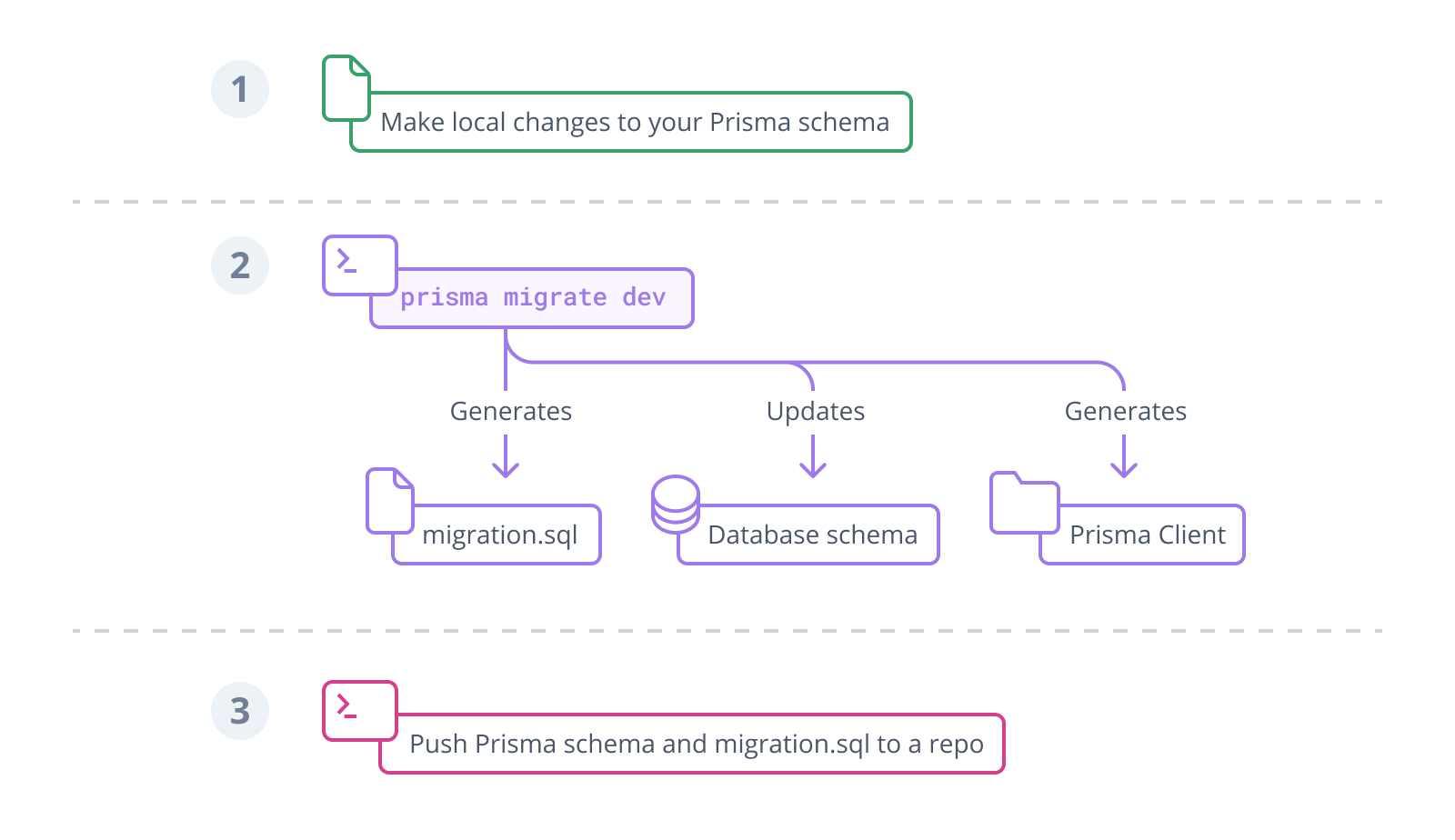
有的時候,你可能會需要針對資料庫的某個欄位做些微的更動
比如說,增加 unique constraint 或者是設置 default value
這些,其實就是資料搬遷的一種
以 Prisma 來說
每一次的搬遷,它都會新增一筆新的 entry
針對該欄位的更新 sql 就會寫在裡面
各個語言其實都已經有不同的 Migration 工具
如 Node.js 裡的 Prisma, Python 裡的 Alembic 以及 Golang 裡的 golang-migrate
Data Migration
不過 Schema Migration 仍然是較為簡單的狀況
真實世界可複雜的多
商業邏輯的改變,資料搬遷的功會比想像中的多
比如說
我們想要仿造 Youtube 的開啟小鈴鐺的功能,使用者可以自由切換要不要開啟通知
因為我們已經有使用者正在使用我們的服務了
所以針對 舊有的使用者,我們必須讓它也可以使用這個功能
所以我們需要針對這些舊有用戶,幫他們新增預設的通知設定
新的使用者,因為初始化的時候已經做了,所以不需要包含在這次的搬遷內容裡面
Database Migration
又或者是資料庫本身的遷移,比方說從 MySQL 遷移到 PostgreSQL
兩邊 metadata 的差異,也是必須要進行處理的
這種要考慮的點與 Data Migration 不太一樣,不過大方向依然是類似的
Preparation
既然你已經知道你要針對哪一個部份做資料搬遷了
你需要做哪一些準備工作呢?
Backup
因為這種商業邏輯的資料搬遷往往伴隨著一定程度的危險
所以做好備份的工作是必要的
最壞的狀況就是,當資料搬遷出了大問題
你已經沒辦法挽回的時候,至少還有一個拯救的辦法
不過要注意的是,當系統升級完成但搬遷卻失敗
使用 backup 復原並不是一個好的辦法
因為你需要考慮到回復會不會造成系統相容性的問題等等的
有沒有 向後相容? 它會不會造成現有服務運作異常
這個問題值得思考
Verify Business Requirement
除了技術方面,你還得要確認商業邏輯的部份
他是不是符合公司的要求
如果條件允許,也必須提及此次系統更新可能的影響
包含它是否商業上可行? 會不會與未來的規劃有衝突等等的
How to do Data Migration?
仔細想想其實也就兩種
- 手動升級
- 自動化升級
其中手動升級是較為不推薦的作法
如果沒有適當的文件,它可能會難以維護
甚至你可能會忘記為什麼這個欄位會是這個數值
自動化升級至少你還有 code 可以查看
而自動化的部份,你可以單純寫 SQL 或者是使用類似 Prisma 這種工具幫你解決
如果遇到複雜的商業邏輯的部份,則可能要寫個小程式執行
Reversibility
在資料搬遷的過程中,你必須要考慮到它是否可以被還原
也就是說,如果搬遷失敗,你必須要能夠將資料還原到搬遷前的狀態
比如說,你新增了一個欄位(新增一個文章分類的欄位),你也應該要考慮到他是否能夠在刪除的情況下正常運作
所以理論上你需要有兩個 script 來處理這件事情
-
upscript- 新增一個欄位以及必要的舊資料升級
-
downscript- 刪除新增的欄位
你可能會好奇為什麼要有 down script
萬一需要 rollback,整個 database 的狀態理應是 乾淨的
以這個例子來說,新增的欄位必須要被剔除
像是 alembic 裡面 migration 的實作
你可以看到說也是有兩個 script 來處理這件事情
1
2
3
4
5
6
7
8
9
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
# ### end Alembic commands ###
Possible Issues
Backward Compatibility
有的時候資料升級,你會遇到無法向後相容的部分
也就是說新的資料格式沒辦法正確的套用到舊有的資料上
倒也不是你資料錯誤導致,而是 資料缺失 造成的
導致說更新完的資料會沒辦法與新版的系統正確的匹配運作
舉例來說,我目前碰到的狀況是我想要 “發文分類” 這個功能
但是早期建立的文章並沒有任何欄位可以區分(比方說 個人空間 還是 公開空間)
這樣的狀況你無從知道這些資料是屬於哪一個分類
無可避免的,這種時候各種做法都會有它的缺點
- 全部搬遷到 個人空間/公開空間
- 保留 NULL 值,更改處理資料邏輯
當然我們能做的,就是盡量將損失降到最低
Data Loss
執行資料搬遷,我們絕對不希望它更改到其他不相干的部份
但它仍然是可能會發生的,所以測試是必要的
針對你搬遷的部份,建立幾筆資料觀察它執行的結果
在上到 production 之前,可以在 dev 以及 staging 環境測試
我個人會推薦,在這些之前,也可以在本機進行測試
Idempotent
最後也是最重要的一點,你的自動化搬遷的執行檔案
它必須要滿足 Idempotent 的條件
何謂 Idempotent? 就是你不管執行幾次,它得到的結果都要是一致的
比如說上面我們提到想要實作使用者的通知設定功能
你絕對不會希望一個使用者有多個相同設定
因此,在設計 migration script 的時候,他要執行的是 upsert
若是寫入的資料不存在,寫入,若存在,則略過或更新部份值
以 PostgreSQL 來說
你可以使用
1
2
INSERT INTO (xxx) VALUES(yyy) ON CONFLICT(zzz)
DO UPDATE SET id = EXCLUDED.id
當你寫入的資料,有比對到一模一樣的資料的時候,它就會選擇使用原本的 id
而這個比對的基礎,是寫在 ON CONFLICT 裡面
注意到,一模一樣的資料的定義是,它必須擁有 unique constraint 進行保護
有時候你要 upsert 的資料根本沒有 unique constraint
這時候其實你別無選擇,你只能先 query 有沒有該筆資料的存在,然後在寫入
當然這時候,使用 transaction 是相對比較好的選擇
有關 transaction 的討論,可以參考 資料庫 - Transaction 與 Isolation | Shawn Hsu
Long Migration Time
當搬遷的資料數量過於龐大
花超過額外預期的時間是有可能會發生的
資料庫系統的更新,因為會佔用一定的連線數量,以及一定的 I/O
系統的反應速度可能會變慢
Off-peak Time
你可以選擇在半夜這種不會有太多使用者在線上的時候,執行系統升級
Migration Checkpoint
或者是 migration 的檔案數量過多,導致執行時間需要拉長
如果遭遇頻繁的資料庫遷移,這種事情是可能發生的
一個解決方法是使用 checkpoint 的機制
我們知道,migration 是基於目前 “資料庫的狀態” 往上疊加的
所以 checkpoint 的概念是,我重設資料庫的狀態,然後以往的 migration 檔案因為狀態改變就不需要執行
這樣就可以減少 migration 的執行時間
為了系統的可用性,我們通常會希望系統的 down time 越低越好
盡可能的提高使用者體驗
Change Data Capture(CDC)
除了進一步優化 SQL 的部分,你也可以使用所謂 CDC 的機制
簡單來說,如果資料過於龐大導致遷移時間過長,系統就沒辦法正確動作
如果可以一邊搬遷一邊提供服務,不就解決這件事情了嗎?
對於有實作向後相容的資料(i.e. Backward Compatibility)來說,這個想法是可行的
如果不相容,根本跑不起來
所以實務上,會有兩台機器在運行
- 一台是目前正在線上服務的資料庫,稱為
source - 另外一台是 “新版” 的資料庫,它會在後面慢慢的將舊版資料升級成新的資料格式,稱為
destination
當 source 資料庫有新的寫入,它會將這筆更新推播到 destination 資料庫
讓兩台資料庫的內容盡量保持一致(為什麼說盡量,因為推播沒那麼快)
這個技巧稱為 Change Data Capture
當兩台機器達到一定的同步程度,就可以把它切過去
這個 cutoff 會有極短暫的 downtime,但是相比其他方法來說,這個影響是最小的
也就是 Blue Green Deployment,可參考 Kubernetes 從零開始 - 部署策略 101 | Shawn Hsu
在 資料庫 - 初探分散式資料庫 | Shawn Hsu 裡面,我們有提到,分散式資料庫的架構下,資料的同步是相當困難的
其中你可以使用 Statement Replication 的機制來達成資料的同步
但是由於自身的機制,它無法處理 non deterministic function 如 NOW() 或是 RAND() 等等的
因此比較推薦使用 Logical Log 的機制來達成資料的同步
而 Logical Log 本身,就可以視為是 Change Data Capture 的資料來源
那這些 Event 資料屆時可以透過 Apache Kafka 以及 Kafka Connect 來同步資料
有關 Kafka 的介紹,可以參考 資料庫 - 從 Apache Kafka 認識 Message Queue | Shawn Hsu
On-premise vs. SAAS Migration
有些產品是落地的,資料並不在我們的控制之下
在這種情況下,資料升級無疑是相當困難的
SAAS 的產品,我們可以直接存取到資料庫本身
而我們很清楚服務內存在著什麼樣的資料
升級失敗復原相對容易且容易掌控
因為執行資料升級的會是開發服務本身的廠商
到了 On-premise 這裡,事情會完全不一樣
客戶並不一定擁有足夠的知識能夠處理,甚至可以說是沒有這樣的知識
支援是相對薄弱的,這時候如果升級失敗將會是一場災難
若是遇到 Backward Compatibility 的問題,無疑是雪上加霜
Data Migration In Kubernetes
如果你的資料庫是在 Kubernetes 內部運行,你可能會遇到跟我一樣的問題
我們的資料庫(i.e. PostgreSQL) 是透過 Helm subchart 來管理的
每一次 $ helm install 資料庫與應用程式會一併的進行安裝
有關 Helm Chart 可以參考 Kubernetes 從零開始 - Deployment 管理救星 Helm Chart | Shawn Hsu
這就導致說,資料升級的這個過程無從下手
什麼意思呢? 就如同 Database migrations in Helm charts using pre-install, pre-upgrade hook 提到的
要執行 migration 需要資料庫先安裝,而且需要在應用程式啟動之前
這本質上是不可能的
因為 Helm Hook 本身並沒有那麼細緻的控制
pre-install 是完全不可行的,因為只有在 hook 完成之後 app 才會開始安裝
而 post-install 有可能 app 已經啟動完畢,但是 data migration 還沒完成,然後造成資料損毀
有關 Helm Hook 可以參考 Kubernetes 從零開始 - Deployment 管理救星 Helm Chart | Shawn Hsu
再來是,Helm Hook 本身的設計也不是要拿來讓你跑長時間的任務
即使你說,沒有啊目前就大概 3 分鐘會跑完也是不適合的,就… 他不是設計給你這樣用的
根據 Question: Long Running Hooks - Yes or No? 你也可以看到
Most of the time, a long running hook (for hours or days) isn’t a good idea.
其實官方是不推薦的,更甚至因為透過 Helm Hook 建立的 K8s Resource 本身是脫離 release 的
也就是說他的生命週期並不是跟著 helm upgrade, helm delete 一起的,你需要手動管理
在 on-premise 的環境這種做法是更糟糕的(可參考 On-premise vs. SAAS Migration)
Kubectl Wait
基本上你會有幾種選擇
- 利用 Kubernetes Job 獨立執行 migration(透過 Helm Hook 控制順序)
- 在 Deployment 中使用
initContainer執行 migration - 在應用程式內部進行 migration(啟動 web server 之前執行)
- 透過 CI/CD pipeline 執行 migration
有關 Job/Deployment 可以參考 Kubernetes 從零開始 - Pod 高級抽象 Workload Resources
有關 CI/CD pipeline 可以參考 DevOps - 從 GitHub Actions 初探 CI/CD
2 與 3 是一樣的,看似可以用但實際上你需要注意到 race condition 的問題
因為如果你需要 scaling, 多個 replica 會執行相同 migration script,沒處理好會導致資料不一致的問題
也同時必須考慮到升級時間過長的問題,可能會被 K8s kill 掉等問題
4 的假設是你的服務是 SAAS 的,落地的情況下根本無法實現
1 的情境其實是默認資料庫沒有跟 app 一起安裝,這種狀況用 Helm Hook 才有辦法
但以我的例子來說,他們是一起安裝的,所以以上都無法使用
好在,我們還有一招 kubectl wait
這個指令可以用於等待資源的狀態達成某種條件
也就是說,其實是可以使用 Kubernetes Job 負責執行 migration
然後 app 的 deployment 使用 kubectl wait 等待 migration Job 完成後再啟動
一開始的時候以下同時執行
- app deployment 安裝
- migration job 執行
- database 安裝
然後流程會變成這樣
- database 先完成安裝(同時 migration job 與 app 都被
initContainer的資料庫檢查 block 住) - migration job 完成執行(app 被執行 kubectl wait 的
initContainerblock 住,等待 migration job 完成) - app 完成安裝(這個時候 migration 已經成功)
K8s Job Lifecycle and ArgoCD Synchronization
雖然使用 Kubectl Wait 可以解決資料庫與應用程式同時安裝,無法進行資料升級的問題
但是這種作法會需要非常小心
如果你的 Job 有設定 ttlSecondsAfterFinished,Job 本身會在這個時間之後被刪除(不是底下的 Pod 而是 Job 本身)
這樣 Kubectl Wait 的判斷就會失效,導致你的主程式起不來(注意到並不是 deploy 才會用到判斷,如果你的 deployment 意外重啟而 Job 已經被刪除,同樣也適用)
搭配上 ArgoCD 這種作法只會更糟,因為 K8s 不允許同名的 Job,所以會無法同步
你唯一想的到的就是加上 ttl 讓 Job 自動被刪除,Argo 才能再次同步
不過問題又回到前面講的
K8s Job 預設是不會清除的
1
2
3
4
5
6
7
8
NAME READY STATUS RESTARTS AGE
pod/sleep-test-vvk98 0/1 Completed 0 4h55m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.43.0.1 <none 443/TCP 4h55m
NAME STATUS COMPLETIONS DURATION AGE
job.batch/sleep-test Complete 1/1 57s 4h55m
所以怎麼辦呢?
你可以在 Kubectl Wait 中指定使用 label 判斷
至於 Job 的名稱可以用 generate name 來生成
這樣就完美繞過以上的所有問題
1
2
3
4
5
$ kubectl wait --timeout=60s --for=condition=complete --timeout=60s \
$(\
kubectl get jobs -l component=sync \
--sort-by=.metadata.creationTimestamp -o name | tail -n1 \
)
挑選 label 為
component=sync的 Job,並且按照 creation timestamp 排序,選擇最後一個
唯一的 drawback 是你會有很大量的 Job instance 存在
透過簡單的 cronjob 去清除是不錯的選擇
這樣你就能夠解決資料庫與應用程式同時安裝,無法進行資料升級的問題了
How Netflix Perform Database Migration
Why Database Migration
Netflix 的 platform team 在 2024 的時候決議要從 Amazon RDS PostgreSQL 遷移到 Aurora PostgreSQL(i.e. Database Migration)
考慮的主要原因有以下
- PostgreSQL 作為 Netflix 廣泛使用的資料庫,有超過
95%的 workload 依賴於 PostgreSQL,遷移過去成本較低 - 因為 PostgreSQL 已經逐漸被廣泛使用,社群支援完整
- Aurora 提供了高可用性以及分散式的特性,可以滿足 Netflix 的需求
- Aurora 目前提供了豐富的功能,以及其未來的規劃滿足 large-scale 的需求,也是 Netflix 所需要的
High Level Migration Plan
既然決定要換,那具體怎麼做?
從 RDS 到 Aurora,主要有兩種作法
- 停止 RDS
 對 RDS 進行快照 從快照建立 Aurora 叢集並恢復
對 RDS 進行快照 從快照建立 Aurora 叢集並恢復 - 建立 RDS read replica 到 Aurora 的 CDC 等到同步差距非常微小之後,停止主要 RDS master 暫停寫入 等到完全追上,將其一 Aurora slave 升級為 master 並恢復
注意到第二點的同步差距,它需要考慮的是一段時間內的差距趨於平穩,而不是單純某個時間點的微小差距而已
兩者最主要的差距是在於 停機時間
RDS 需要完全暫停,將全部資料複製並在 Aurora 上恢復,在此期間無法提供服務
反之,使用 CDC 機制可以做到 “幾乎” 無停機遷移
當然,CDC 的機制複雜程度會被拉高,需要額外考慮其他問題
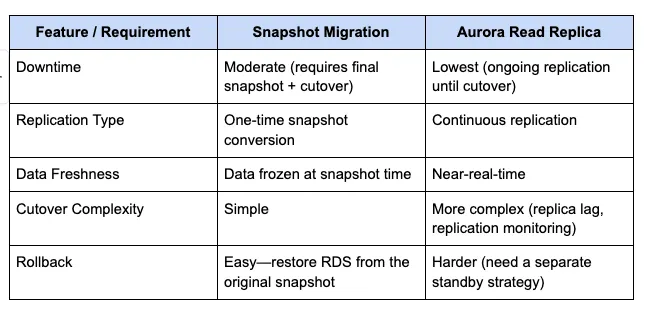
最後他們選擇 CDC 的機制,以最大程度減小 downtime
Database Migration
當然,為了避免各種意外,首先一定是先做完整的備份(如同我們在 Preparation 提到的)
再來就是要先準備好連線參數這些,要注意的是,資料這層 Netflix 是透過 Data Access Layer 隔離的,所以對於 application 來說,它不需要更動任何東西
只是 DAL 內部需要更新這樣,兩個資料庫的參數並不完全長一樣,所以這是需要事前調整的理由
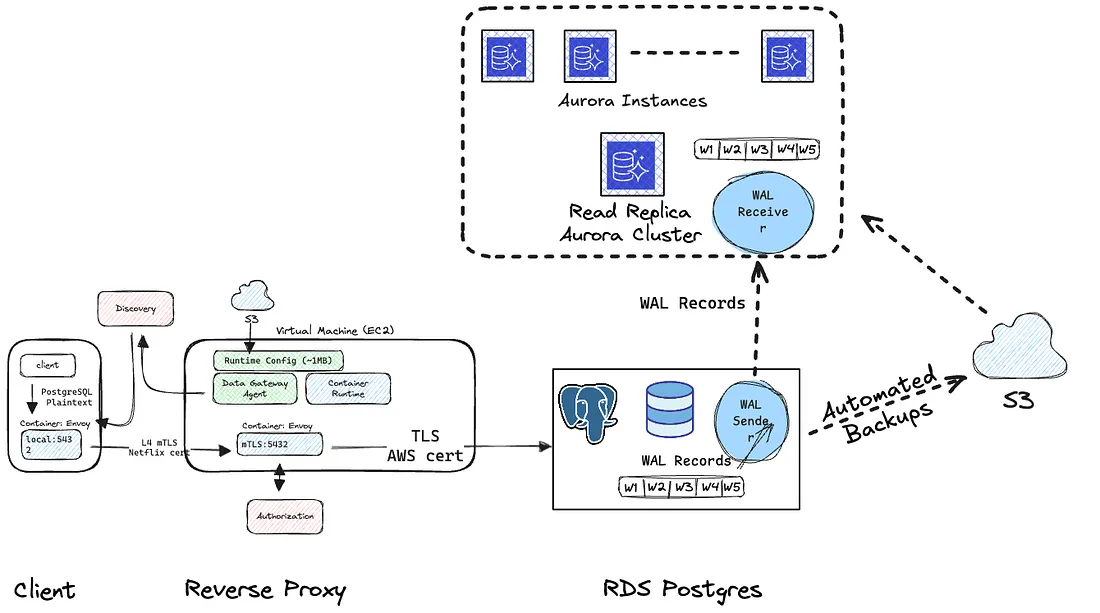
搬遷的過程就如同 Change Data Capture(CDC) 說明的一樣
具體來說是透過 WAL(Write Ahead Logs) 來同將資料同步,過程中 RDS 依然是主要的資料庫
最重要的是切換對吧
application level 會被暫停,但這樣真的足夠嗎?
對於 Netflix 來說,它必須要做到除了 platform team 以外沒有任何人能夠存取 db
因此,他們在 infra level 也進行了阻擋(避免,比如說,錯誤的設定導致連線還開著,沒有通知到維護時間或者是連線還沒斷開等等的情況)
確保說,沒有任何連線到資料庫,避免任何資料意外的沒有被同步到更甚至損毀的程度
關閉之後不能馬上切換,因為同步的過程會受到非常多因素干擾,最常見的是由於網路問題導致同步稍微變慢沒有跟上
所以會需要等待一段時間,到所有更新都同步,才能切換
怎麼判斷其實也很簡單,當 “待處理的 WAL 大小為 0 的時候” 就代表已經完成同步了
有趣的是,他們透過 metric 觀察到,三不五時還是會有 64MB 的資料沒有被同步到,如下圖
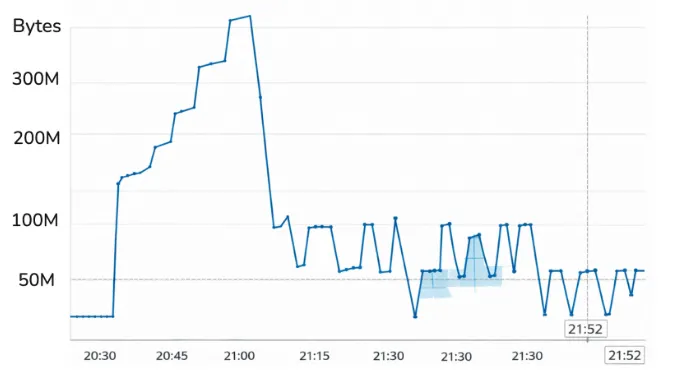
而原因在於,PostgreSQL 的 WAL 預設每五分鐘,就會執行 WAL switch
idle 期間沒有任何新的資料(因為你切斷所有連線了),所以下一個五分鐘,執行 WAL switch 的時候,會寫入一個空的 WAL segment
而這個大小,恰好是 64MB,所以在 metric 上面你就會看到這樣的結果,但它本質上就是已經完成同步了
到這時候,我們就可以很確信同步已經完成,可以執行切換了
基本上你需要確認說,這個 0
WAL switch 的間隔 5 分鐘,如果對於那些不太能忍受太長 downtime 的系統來說,可能會是個問題
可以調整他的 idle 時間,及早確認 pattern 並提早結束停機
對於 application team 來說,這個切換跟他們無關,因為所有的資料庫存取都是透過 DAL 這個 reverse proxy 來進行
連線資料那些也基本都是在 DAL,所以不論是程式碼還是資料庫參數,都不需要更動
data gateway 會自動將他們導向新的 Aurora 資料庫
Unexpected Migration Failure
即使有縝密的規劃與安排,他們還是在搬遷的過程中遇到了點小插曲
搬遷過程中,觀察 metric 發現到,”待處理的 WAL 大小” 一直偏高
這意味著,搬遷需要花費更長的時間才能完成
而造成這個的元兇是一個 inactive Logical Replication Slot
Logical Replication Slot
Write Ahead Log(WAL) 裡面紀錄的是每個 “事件”
他是一個事件記錄簿,除了當資料庫出意外的時候可以使用它恢復資料,也可以作為 Change Data Capture(CDC) 的資料來源
每個 CDC 的 consumer 都需要紀錄說,自己已經讀取到 WAL 的哪個位置
這個位置的紀錄被稱作 logical replication slot
WAL 的資料會同時被很多人讀取,所以 slot 也會有很多個
WAL 的檔案大小不可能無限大,它會需要定期清理
它哪時候該被清理? 就是全部人都已經讀取過得時候 + checkpoint 已經寫入的時候(為方便討論,這邊僅考慮 slot 都已經讀取過)
當全部的 CDC consumer 都已經被讀取過之後,就能夠視為安全,可以被清理了
The Crisis
而恰好就是因為 Logical Replication Slot 的關係,導致了這次的搬遷卡住
出事的是一個 inactive 的 slot,由於清理機制是需要 所有 logical replication slot 都已經被讀取過 才能清理
導致說 metric 怎麼計算就是還有很多 WAL 沒有被同步,加上其實 RDS 在當下還是繼續接收資料,待處理資料量直線上升
要解決也很簡單,手動移除該 slot,之後整個搬遷過程就很順利了
也因為採取的是 CDC 的機制,所以其實對客戶來說他們沒感覺到異常
How to Migrate CDC Consumer and Replication Slot
我們知道 Change Data Capture(CDC) 是將資料庫的事件推播出去的方法
但是現在換了一個資料庫,對於這個推播會有影響嗎?
意思是說,Logical Replication Slot 是用來標記說我看到 WAL 的哪個位置,當換了一個資料庫,這個標記還有效嗎? 還能夠銜接上去嗎?
理論上來說是不行的,所以其實 Netflix 他有一個專門的 CDC 服務稱為 datamesh
因為 consumer 是從 datamesh 接收資料的,所以對它來說 Slot 的問題不是他要考慮的
一開始,會先暫停 CDC consumer 並且移除該 Logical Replication Slot
此時 CDC consumer 一樣是穩定的不會斷線
當新的資料庫上線,因為舊的 slot 已經被移除,而且也不能繼續用因為是新的資料庫,所以會重新建立新的 Logical Replication Slot
並且為了銜接順利,會將全部資料包裝成事件,重新推播出去(稱為 refresh event)
為什麼要移除 Logical Replication Slot?
舉例來說,Unexpected Migration Failure 提到的情況,如果沒有移除 slot,清理機制就不會執行,導致說 metric 怎麼計算就是還有很多 WAL 沒有被同步
不要誤會,重新推播的目的 不是因為資料庫的資料不一致,而是要讓 事件重新推播 給下游
full backfill 可以讓下游與上游擁有 一致且乾淨的 baseline,因為推播是基於已經存在的資料做出改變,如果 baseline 不一致,後續的推播就會有問題
並且下游的 consumer 收到這些重複的事件應該要能夠處理(i.e. Idempotent)
類似於一個完整的 reset 這樣
References
- Hassle-Free Database Migrations with Prisma Migrate
- What is data migration?
- Migrations
- COSCUP 2025 - Zero‑Downtime Online Schema Migration in PostgreSQL
- [資料工程]獲取資料庫所有異動記錄 — Change Data Capture(1)
- Lab 4.2 - A Simple DAG Workflow: apply workflow with generate name
- Automating RDS Postgres to Aurora Postgres Migration
Leave a comment