資料庫 - 初探分散式資料庫
Distributed System
Scale Out(Horizontal Scale) 的概念是利用多台電腦組成一個龐大的網路,進行運算提供服務
這個網路,稱為 cluster
注意到 cluster 跟 distributed system 在定義上是有所不同的
- cluster
work as a single system
- distributed system
cluster 為 distributed system 的一種
分散式系統通常由網路將節點(node)連接起來,提供服務
Brief Introduction of Issues with Distributed System
多節點在設計上需要注意很多事情
比如說最簡單的資料複製的問題
我有很多個節點,我希望不管我 query 哪一台,資料永遠會是一致的(i.e. Consistency)
我要怎麼確保並發(concurrent)讀寫的時候,衝突得以正確的被解決?
又或者網路出問題
我的系統是不是還能 work?(i.e. Availability 以及 Partition Tolerance)
更甚至節點掛掉怎麼辦?
有關分散式系統中,會遇到的問題
可以參考 資料庫 - 從 Netflix 的 Tudum 系統看分散式系統中那些 Read/Write 問題 | Shawn Hsu
CAP Theorem
CAP Theorem(又名 Brewer's Theorem),是一個分散式系統的 trade off 規則
前面提到了一些分散式可能會有的問題,所以不難發現,使用分散式系統是會有代價的,而這個代價分為三種
Consistency(C)
資料的正確性對於某些系統而言,是很重要
如同先前提到的,要怎們確保資料在每一個節點都是正確的呢?
另外,它需要馬上正確嗎? 還是它可以提供 最終正確性(Eventual Consistency) 就好?
Eventual Consistency 指的是總有一天它會同步完成
較正式的定義是: 暫停寫入,給一點時間,follower 最終會同步完成,保持資料一致
Availability(A)
可用性,指的是說,即使有部份節點意外下線(可能是系統重啟等等的)
我的系統仍然可以順暢的處理服務
Partition Tolerance(P)
分區容錯性的意思是,節點之間斷開連線(可能是網路問題)
系統依然可以正常的運作
你會想,它長的跟 Availability 可真像
回顧 distributed system 的定義,是指 “共同合作達成某個目標”
所以一件事情可能仰賴多個節點(每個 node 各負責不同的事情)既然是 “共同合作”, 所以萬一途中有個節點無法建立連線
那麼目標就無法達成,因此 partition tolerance 是在確保這件事情
以上三種代價,根據 CAP Theorem 所述,分散式系統必須犧牲其中一個代價
因此,可以得知有三種系統
| System Type | Description |
|---|---|
| CP | 犧牲 Availability |
| AP | 犧牲 Consistency |
| CA | 犧牲 Partition Tolerance |
具體要用哪一種,取決於你的需求
不過 CA 系統較少使用,因為其犧牲了 Partition Tolerance
分散式系統中,大量的依賴了網路的基礎建設,因此網路出問題是不可避免的,所以基本不會選擇 CA 系統
How to Benefit from Distributed System
分散式系統主要可以透過 Replication 以及不同的 Architecture 來最佳化
注意到他們不是二選一,比方說你可以同時使用 Single Leader 搭配 Replication
Replication
既然我們討論的 scope 是資料庫嘛,一定會遇到資料要複製到不同節點上的問題
擁有相同資料的節點稱為 replica(副本)
一般而言,資料複製可以簡略的分為兩種類別
| Category | Description |
|---|---|
| Synchronous | 當每個節點都同步完成之後,才視為操作完成,並返回 client |
| Asynchronous | 只要當前 node 寫入之後,立即返回,其餘節點的同步依靠背景程序 |
至於資料複製的路徑有這三種(如圖所示)

上圖適用於 Multi Leader 的複製(因為 Single Leader 的路徑是唯一的)
環狀跟星狀的會有缺點就是只要其中一個節點壞掉,它就不能往下同步
實務上,資料複製有幾種作法
一一看吧
Statement Based
最直覺想到的作法就是將 SQL 語句(e.g. INSERT INTO User xxx VALUES xxx)同步到各節點上,然後每個節點自己執行
但是要注意到一些 non deterministic function 如 NOW() 或是 RAND()
這些函數在不同節點上,它不一定會回復一樣的值,即使它用 Synchronous 的方法也一樣
解決辦法也算簡單,只要使用固定數值予以取代即可
Write-ahead Log
為了避免系統掛掉之後資料遺失,通常會有所謂的 log file
而資料庫系統也有,稱為 write-ahead log
真正寫入磁碟之前,會額外存一份在 log file 裡
而此類 log file 的內容通常會更靠近底層
因此它與
- 資料庫系統
- 資料庫系統版本
是緊密耦合的
在遇到不同系統,不同版本的節點,要做升級只有兩條路
- zero downtime upgrade
- 停機升級
 這種狀況要盡量避免(因為停機等於中斷服務,等於沒錢)
這種狀況要盡量避免(因為停機等於中斷服務,等於沒錢)
Logical Log
跟 Statement Based 的概念類似
不同的是 logical log 會將真正的 values 算出來
1
2
INSERT INTO User(userID, username, created_at)
Values(1, "ambersun1234", "2023-08-07 15:40:06")
可以看到這裡的 created_at 我先把它算出來
然後這串數值同步到其他節點上,就不會遇到 non-deterministic function 的問題了
記得 log 裡面要包含能指到特定 row 的資訊哦(e.g. primary key)
有關 index 的討論,可以參考 資料庫 - Index 與 Histogram 篇 | Shawn Hsu
Store Procedure Based
這個方法提供了一些客製化的彈性
就是說前面幾種都是完整的資料複製,透過 Store Procedure(SP) 可以對 log file 進行特定的操作
比如說你只想同步某幾筆這樣
由於其高度客製化的特性,也有不少人選擇使用它
有關 Store Procedure 可以參考 資料庫 - 最佳化 Read/Write 設計(軟體層面) | Shawn Hsu
Architecture
Single Leader(Master Slave)
叢集裡面,選一個節點當 leader(master), 剩下的人都 follower(slave)
這樣分要幹啥子呢
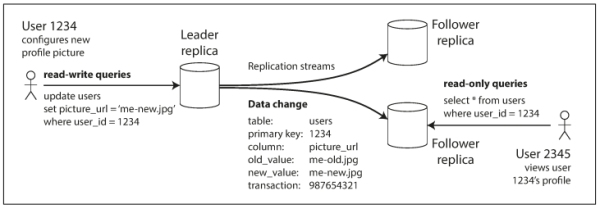
他的目的在於區分讀寫
write 只找 leader, 而 read 可以隨便找任意一個都行
這樣的好處在於說它可以 提昇讀取的效率
壞處也很明顯 寫入的速度會被受限(但寫入不會有衝突)
遇到節點損壞的時候,勢必要將其中一個 follower 升格為 leader
升格的過程你可能會遇到一些問題,舉例來說,有可能 old leader 沒有意識到它已經被降級了
它仍然在執行 leader 的功能,這就會造成同一時間有兩個 leader 存在的問題
而這稱為 Split Brain(腦分裂)
有關 Split Brain 的討論,可以參考 資料庫 - 從 Netflix 的 Tudum 系統看分散式系統中那些 Read/Write 問題 | Shawn Hsu
Multi Leader

既然 Single Leader 僅解決了讀取的效能問題
那麼允許多個節點提供寫入的功能不也行嗎
當然是沒問題的
使用 multi leader 的方法可以大幅度的的高讀寫的效能
它僅有一個缺點,寫入會有衝突,而這是一個很大的缺點
就像 git 在使用的時候一樣,如果多個人對同一份檔案進行更改
那要以誰為主?
因此實務上,Multi Leader 會增加系統的複雜度
Leaderless
顧名思義,沒有所謂 leader(master) 的存在
亦即每個節點都可以接受 read/write
通常實作都是同時的將請求發給 所有的 node
或者是由 coordinator 協助轉送 request
那我要怎麼確保每個節點的資料是一致的?
Multi Leader 會遇到的問題,我也會遇到
那它不就跟它長的一樣了
一樣都允許 並行寫入,一樣都會遇到 衝突
差別在於,當遇到衝突的時候
- Multi Leader 僅需要 leader 們解決
- Leaderless 需要全體成員參與決策
How Distributed System Ensure Consistency
所以你有多個節點,讀寫資料是一個問題
每台機器上保存的資料可能都有一點落差(因為同步的問題),你要怎麼確定 “哪一個資料” 才是正確的?
前面看了 single leader, multi leader, leaderless
他們要怎麼互相的協調才能提供 正確的資料?
Quorum Consensus
想的簡單點,Quorum 共識機制其實就是 取得多數人的同意
什麼意思? 當某個新的資料要寫入資料庫的時候,要怎麼確定資料已經寫入?
10 個節點只有其中 1 個人說寫入了,剩下 9 個人都說還沒
這樣應該不會視為是成功寫入
當多數人都同意寫入成功之後,這個資料才算是成功寫入
這就是基本的 Quorum Consensus 的概念
好處在於說,當一個節點掛掉的時候,其他人還認得說有這件事情發生過
換言之,資料不會不見
n 個節點,需要取得
-
w個節點確認寫入成功才算數 -
r個節點確認讀取成功才算數
要保證每次的讀取都有 最新 的值,可以遵照這個公式 w + r > n
他可以確定至少有一個節點擁有最新的資料(前提是 w 跟 r 的副本有重疊到)
Sloppy Quorum
但是網路是不可靠的,網路斷線是很常發生的事情
也就是說容錯能力是有限的,斷個網 quorum 就失效了
畢竟你就是要那麼多節點幫你確認
Tolerance to Node Failure
假設 11 個節點
-
w有 6 個節點 -
r有 7 個節點
那最多你可以容忍 4 個節點掛掉
因為
-
w的情況下需要 6 個節點是好的,總共是 11 個節點,4 個壞掉,7 個還是好的,所以是 有餘欲的 -
r的情況下需要 7 個節點是好的,總共是 11 個節點,4 個壞掉,7 個還是好的,所以是 剛好足夠的
所以一個作法是,我一定需要 “那個” 節點嗎?
我可以有一個 hot standby 的節點,當 online 的節點掛了就將資料同步過去(i.e. Failover)
是不是也算滿足 quorum 了呢?
事實上也的確如此
等到節點恢復的時候在將資料同步回來即可
Consensus Algorithm
單靠多數決 是無法 確保資料一致性的,因為最重要的還有 順序 的問題
Quorum Consensus 並不保證資料順序
這會在很大程度上造成資料不一致的問題
我們更想要的共識是,每個節點都可以依照相同順序,並保證 exactly once 的寫入機制
在 資料庫 - 從 Netflix 的 Tudum 系統看分散式系統中那些 Read/Write 問題 | Shawn Hsu 我們提到了 Atomic Broadcast 的概念
它可以保證說每個節點 收到資料的順序
配合上 exactly once 的寫入機制,我們則稱之為 全序廣播(Total Order Broadcast)
Raft, Paxos 以及 Zab 等等都是全序廣播的實作
“每個節點收到資料的順序”?
這是不是意味著,要有一個 leader 來決定順序?
沒錯,所以 Leaderless 以及 Multi Leader 通常不會使用 consensus,反而會採用 Quorum Consensus
涉及到 leader 的問題,選舉就是一個必要的流程
如同 Single Leader 中提到的,當 leader 掛掉的時候,需要選出新的 leader
這邊選舉會需要透過 Quorum Consensus(因為選舉本質上是多數決對吧)
然後也要處理腦分裂等等的問題
為了解決容錯轉移造成的資料遺失,通常會從選舉委員會裡面挑選新的 leader
委員會內部的人通常被視為是 “足夠跟上 leader 的進度的 follower”
如果要了解共識機制,建議可以看看真實世界的例子,比如說 KRaft 的實作
可以參考 資料庫 - 從 Apache Kafka 認識 Message Queue | Shawn Hsu
Trade-offs
共識機制的強大依賴於各種強力的機制進行保護
如選舉機制、全序廣播等等
但是這些措施會對系統帶來額外的負擔
-
容錯轉移有可能會導致資料遺失 -
全序廣播會要求額外的確認,寫入性能會有影響
所以有些人會為了這一丁點效能問題,選擇不使用共識機制
採用 Quorum Consensus 搭配 Last Write Wins 的機制(比如說 Cassandra)
Consensus Outsourcing
共識機制可以交由第三方管理,如 ZooKeeper
早期 Kafka 是使用 ZooKeeper 來做這些事情的
不過後來因為效能問題考量,改將 Raft 實作在 Kafka 內部(i.e. KRaft)
Different Approaches of Increasing Demands on Computer System
![]()
ref: Upgrade Button
Scale Up(Vertical Scale)
Random I/O vs. Sequential I/O
硬碟的讀寫有分隨機讀寫以及連續讀寫
他們的差別也很好理解
連續讀寫 - Sequential I/O 亦即 你要找的資料就在下一個,所以他是連續的
而 你要找的東西不在下一個區塊,就是屬於 隨機讀寫 - Random I/O
對於硬碟效能來說,這兩個讀取效率如果越高代表效能越好
你可以使用 CrystalDiskMark 這套軟體測量硬碟讀寫的效能
那麼哪些東西屬於隨機讀寫,哪些又是連續讀寫呢?
-
連續讀寫 - Sequential I/O
- 當你需要 copy 大檔案到,比如說你的隨身碟上面,這時候使用的就會是連續讀寫(因為你的一個檔案肯定是一個 byte 接著一個 byte 的)
-
隨機讀寫 - Random I/O
- 其他剩下的基本上都屬於隨機讀寫(比如像是 掃描病毒 之類的)
- 其中 資料庫 也是屬於隨機讀寫
值得注意的是
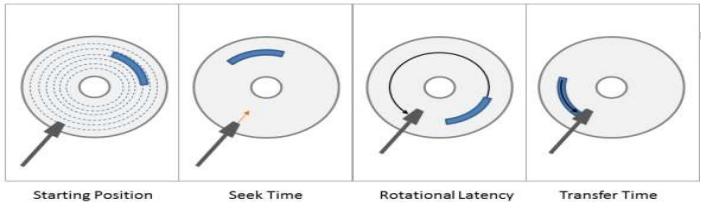
傳統硬碟 HDD,針對隨機讀寫,會有影響
主要的原因是因為 HDD 採用機械結構,每一次的移動讀寫頭都是需要時間的
Disk Seek 在 HDD 幾乎不可能平行運算,因為機械裝置只有一個
- Seek Time 尋找 Track 的時間
- Rotational Latency 尋找 Sector 的時間
- Transfer Time 資料傳輸至記憶體的時間
至於 SSD 因為沒有讀寫頭這種機械裝置(而是採用 Nand 顆粒),所以不會有這個問題
單純的堆料,提升單台伺服器的效能的方法
它終究是有其限制所在的,你無法加 “無限” 顆硬碟或 CPU 在一台電腦上
但你不得不承認他是一個簡單又暴力的解決辦法
這裡列出幾個有可能出現的瓶頸點供參考
| Hardware | Description |
|---|---|
| CPU | 為了要能夠處理從 Disk 撈出來的資料,CPU 扮演了一個很重要的角色,時脈的高低取決於你能夠以多快的速度處理這些資料 |
| Disk | 毫無疑問的,硬碟是很重要的,從以前的 Magnetic Tape 磁帶,Hard Disk Drive 傳統硬碟 到現在的 Solid-state Drive 固態硬碟,硬碟速度越高,代表能夠處理的越快速 |
| Memory Bandwidth | 當 memory 的頻寬來不及寫入 CPU cache, 這時候它就有可能為成為瓶頸所在。不過,通常這個不太會發生 |
Scale Out(Horizontal Scale)
一台不夠? 多台來湊!
多台的架設成本可能會比升級 CPU, 硬碟等等還要來的划算
也因此 scale out 也成為現今的主流選擇之一
Summary

ref: https://www.researchgate.net/figure/Scale-out-storage-compared-to-scale-up-storage_fig1_273702105
References
- 資料密集型應用系統設計(ISBN: 978-986-502-835-0)
- 內行人才知道的系統設計面試指南(ISBN: 978-986-502-885-5)
- Optimizing for Random I/O and Sequential I/O
- 【恐龍】理解 I/O:隨機與順序
- Difference between Internal and External fragmentation
- 15.11.2 File Space Management
- MySQL: What is a page?
- How does mysql indexes turn random I/O into sequential I/O
- Can we calculate the bandwidth for a CPU?
- SDRAM 與 DDR:他們之間有何差異?
- Cpu cache and memory bottleneck
- Interview question: How to scale SQL database to allow more writes?
- Difference between Distributed and Cluster? What is a cloud computing platform? Distributed application scenarios?
- CAP theorem - Availability and Partition Tolerance
- Quorum & Raft & Paxos
Leave a comment