Kubernetes 從零開始 - 在分散式的世界實現 Zero Downtime 路由管理
Proxy
Proxy 是一個中間人,負責處理 client 與 server 之間的溝通請求
相比於 client 直接與 server 溝通,Proxy 的優勢在於可以進行流量控制、負載平衡、安全性控制等
他可以分為兩類 Forward Proxy 以及 Reverse Proxy
Proxy(network level) 是負責全部的流量,而 middleware(application level) 只有負責該次 request/response
Forward Proxy
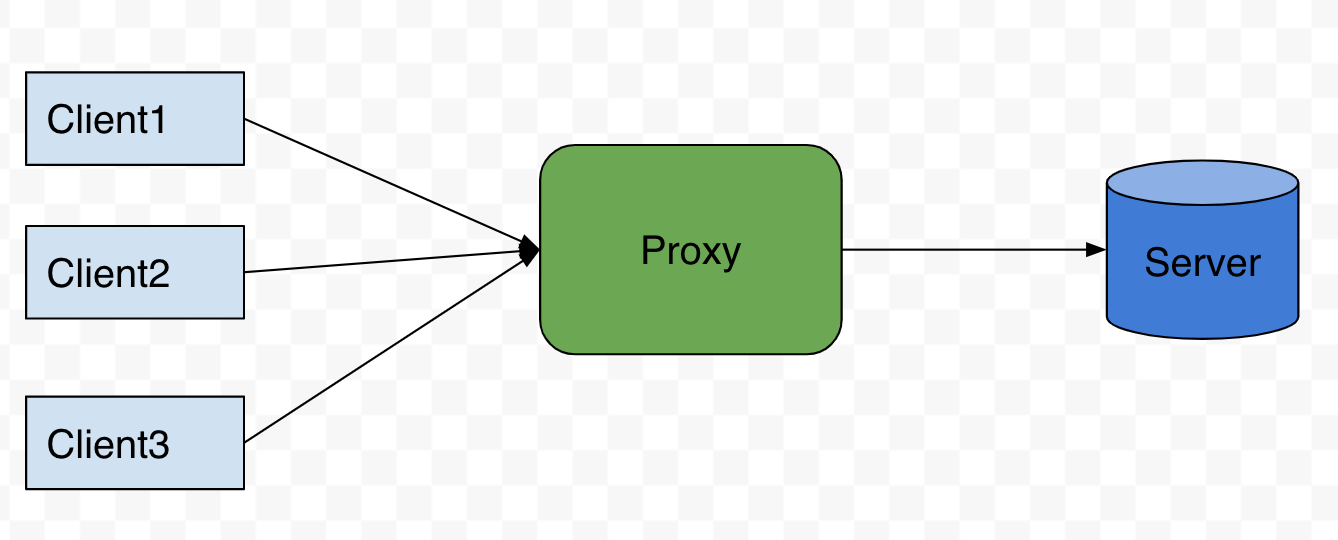
ref: 系統設計 - 正向代理跟反向代理
正向代理是負責處理從 “client” 發出去的流量(換言之就是處理 Outgoing 的流量)
如果遇到說你不希望 server 可以知道 client 的資訊,就可以使用正向代理
所有的 client 都會先經過 forward proxy 再轉發到 server
常見的策略是 forward proxy 會將 client 的 ip 轉換成自己的 ip,藉此隱藏 client 的資訊
Reverse Proxy
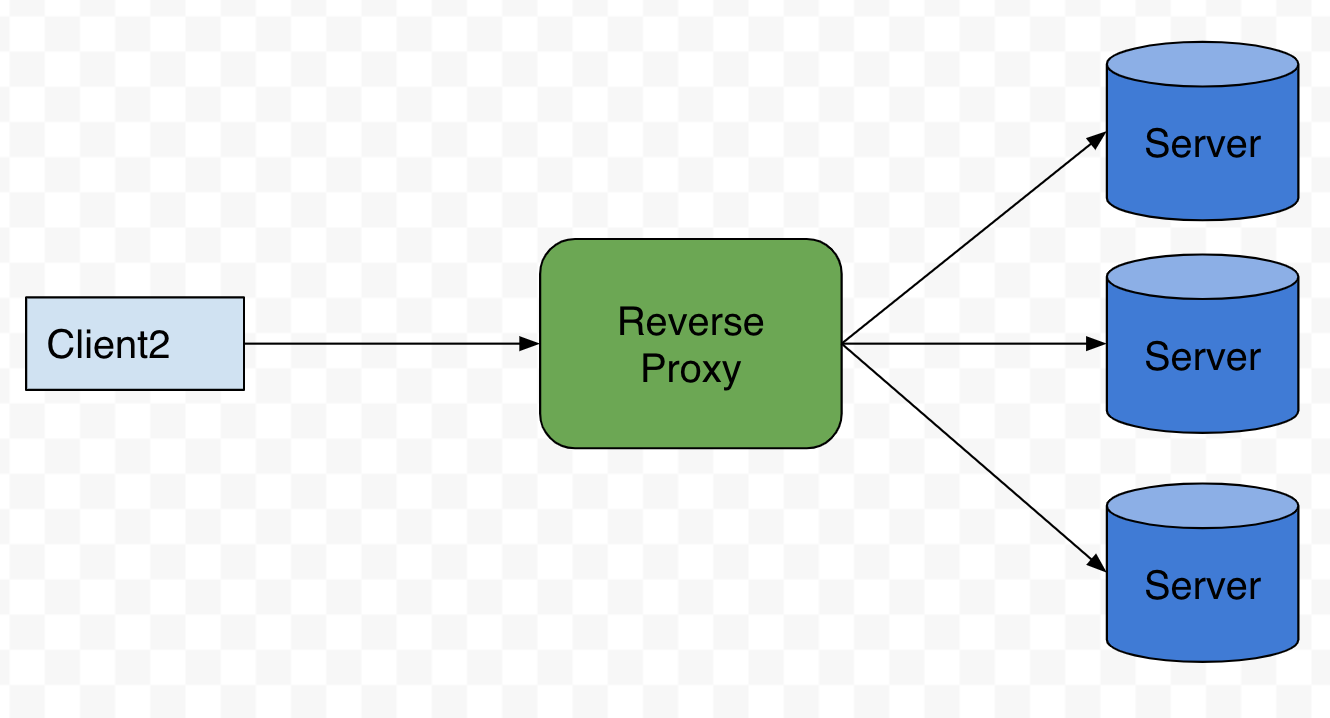
ref: 系統設計 - 正向代理跟反向代理
反向代理則是負責處理進到 “server” 的流量(換言之就是處理 Incoming 的流量)
所有的 request 都會先經過 reverse proxy 再轉發到後端
這樣的好處是可以隱藏後端 server 資訊,以及進行負載平衡(可參考 Load Balancing)
你可以決定要將 request 導向哪一個 server
使用 Nginx 實現 reverse proxy,如果你需要保留原始 request 資訊
可以利用 proxy_set_header 幫你加Host以及Connection
Load Balancing

負載平衡是一種常見的增加伺服器吞吐能力的手段
他的假設是你的應用程式部屬在 多台機器 上
你不會希望只有其中一台伺服器很忙而已
因此負載平衡會將大量的 request 盡量均勻的分佈在所有 worker(機器) 上面
當新的機器加入的時候(scaling),它也能夠分攤現有的工作量,使得吞吐量得以提昇
Load Balancing Methods
基本上負載平衡的算法分為靜態以及動態兩種
- 靜態:根據伺服器的負載能力來分配工作量,例如 Round Robin, Weighted Round Robin, DNS Round Robin
- 動態:根據動態的資訊來分配工作量,例如 Least Connection,Sticky Session
為什麼 Weighted Round Robin 是靜態的?
因為你沒辦法動態調整 CPU Memory 這些資源分配,並且 load balancer 本身也沒有辦法知道伺服器的負載能力
Round Robin
Round Robin 的算法就是,每個人都有一小段時間服務
在作業系統是排程算法之一,在負載平衡的世界也有類似的身影
因為你的伺服器可能有很多個,套用 Round Robin 的概念就會是
Server A 先服務,下一個給 Server B,再來給 Server C,以此類推
Weighted Round Robin
Round Robin 的缺點是,他沒辦法根據不同伺服器的負載能力來分配工作量
比方說 Server A 擁有更好的 CPU 更多的 RAM, 理論上他要負責更多的 request
所以 Weighted Round Robin 就是為了解決這個問題而誕生的
他可以給不同的伺服器一個權重,權重高的就會被分配到更多的 request
DNS Round Robin
一個 domain name 可以指定多個 ip address
當 client 請求該 domain name 的時候,DNS 會回應一連串的 ip address
client 會隨機選擇一個 ip address 進行連線
所以透過這種方式就可以達到基本的負載平衡(DNS Round Robin)
那你也可以加 Weighted Round Robin 的概念進去
有關 DNS Round Robin
可參考 重新認識網路 - 從基礎開始 | Shawn Hsu
Least Connection
Load balancer 會根據每一台伺服器當前的連線數量判定說要不要將 request 轉發過去
對比 Weighted Round Robin 來說,他可以動態的調整伺服器的負載能力
不會只依靠單一的權重來決定,而是會根據伺服器當前的連線數量來決定
Sticky Session
執行 load balancing 如果碰到 session 這種東西可能會有一點麻煩
假設你的 session 是儲存在 server 本身的,那問題可大了
多台的機器做 load balancing 意味著你下一次 request 到後端,可能是不一樣的 server 在服務
此時,server B 並沒有你在 server A 上面註冊的 session
因此你可能會遇到一些存取的問題
這個時候你會希望,client A 永遠是由 server A 服務,並不會由其他伺服器接手
所以 sticky session 的用意就是這個
同時 Nginx 也在 Plus 的服務中提供相關服務,可參考以下文件 Enabling Session Persistence
雖然現在實務上,因為 HTTP 本身 stateless 的特性
搭配 token 驗證身份的方式,使得 sticky session 較少見
Routing in Kubernetes
Kubernetes Service Discovery
針對 cluster 內部的 Pods,你可以透過定義 Service 來讓外部進行存取
那 Service 是如何知道有哪些 Pods 的呢?
在 Service 建立之初,control plane(i.e. EndpointSlice Controller) 會在有 selector 的情況下自動幫你建立 EndpointSlice 這個 Resource
因為 Pod 本身還是有自己的 ip address,為了能夠讓 Service 能夠轉接到 Pod 上面
這些資訊是被儲存在 EndpointSlice 裡面(其他的資訊例如說,conditions, hostname, nodename 以及 zone)
EndpointSlice 的前身是 Endpoints
Pod 是 ephemeral 的,所以即使你有紀錄 Pod 的 ip address
他也可能被移除以及重新加入,然後紀錄就會失效
EndpointSlice Controller 會負責監控這些資源的變化,當相關的 Resource 有更動,controller 就會重新調整 EndpointSlice 的資訊
使得這個紀錄永遠都會是 up-to-date 的
有關 controller 可以參考 Kubernetes 從零開始 - Informer 架構以及 Controller Pattern | Shawn Hsu
這個紀錄必須讓其他的節點也知道,kube-proxy 依賴於 EndpointSlice 進行內部路由
每個節點必須積極的同步這些資料,為了確保傳遞的過程是輕量的
所以新增會優於更新,因為新增一個全新的 EndpointSlice 比更新多筆 EndpointSlice 來得更輕量
EndpointSlice 本身只會存有 100 筆資訊(可以調整),如果超過,則會切割成多個 EndpointSlice
在執行路由的時候,如果你想要維持低延遲的特性,一個方法是 server 就在你家旁邊
這樣就不會有跨區域的網路延遲
在 Kubernetes 中,你可以在 Service 裡面設定 annotation service.kubernetes.io/topology-mode: Auto 來達成
EndpointSlice Controller 會負責在 record 旁邊附加 “hint” 來表示這個 Pod 的拓樸資訊
然後 kube-proxy 會根據這些 hint 來決定要如何路由(i.e. TAR, Topology Aware Routing)
當然也不是說設定 annotation 就有用,比方說如果 node 沒有 topology.kubernetes.io/zone 的 label,那麼 TAR 就無法使用
限制其實還滿多的,可以參考 Safeguards 以及 Constraints
Terminology Ingress vs. Egress
通常在講 network traffic 的時候,早些年 inbound/outbound 的說法比較常見
現在我們會使用 ingress/egress 來表示
根據 When (and why?) did in-/outbound become ingress/egress? 上的討論來看
bound 類的說法比較像是這是終點的意思,而 gress 類比較是 “經過” 的意思
所以
ingress= 流入的流量egress= 流出的流量
流入哪? 流出哪裡呢?
端看你怎麼界定那個邊界
邊界也可以是路由器、一台虛擬機或一個集群
不要將 Ingress 與 Kubernetes Ingress Resource 混為一談
Kubernetes Ingress Resource 是一個 Kubernetes Resource
用於定義不同的路由規則以轉發 HTTP/HTTPS 的流量
但 Ingress 這個單詞的意思已經演變成一種更為廣泛的概念,所以我們會以這個為準
From Service to Ingress Controller
Service 能做到的有限,比方說他沒辦法客製化路由規則
比方說我想要 /api 到 Service A,然後 /admin 到 Service B
基本上你需要額外的工具輔助達到類似的效果
Kubernetes 沒有內建這種工具,取而代之的是所謂 Ingress Controller
流入集群內部的流量統一會先經過 Ingress Controller 進行處理(所以他是一個 Reverse Proxy 的概念)
你可以自由選擇不同 vendor 的 solution, 比如說 Ingress Nginx Controller 或者 Traefik Ingress Controller
基本上都支援基礎的路由設定,更進階的 load balancing、logging、 L4 routing 以及 TLS 等等的看各家實作
有關 L4, L7 可以參考 重新認識網路 - OSI 七層模型 | Shawn Hsu
除了進階的功能以外,最基本的 L7 路由是由 Kubernetes Ingress Resource 定義
其實你可以注意到,Ingress 並不是要取代 Service,而是互補的
底層還是要依靠 Service 來進行轉發
如果要使用進階的功能,內建的 Ingress 可能不足以描述
所以不同 vendor 可能會使用其他資源甚至是 CRD,比如說 Apache APISIX 有 ApisixRoute 資源
有關 CRD 可以參考 Kubernetes 從零開始 - client-go 實操 CRD | Shawn Hsu
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
Ingress Controllers
Ingress Nginx Controller
Ingress Nginx Controller 就是以 Nginx 為基礎的 Ingress Controller
基本上這個 controller 的主要目的是根據不同的 Resource 生成 nginx.conf 的設定檔
這些 Resource 包括 Ingress, Services, Endpoints, Secrets 以及 ConfigMaps
每一次 Resource 有變化,Controller 就會重新生成設定檔
這樣的做法會一直重複生成,雖然很耗資源,但這是必要的,因為你沒辦法知道 Resource 的變化會不會最終導致 nginx.conf 的變化
也有可能沒改變? 那這樣就不需要更新設定檔了(不過計算還是需要的)
實作上 Ingress Nginx Controller 是使用 Informer 進行處理
註冊 EventHandler 來監聽,並且通過 Ring Buffer(RingChannel) 傳遞需要處理的資料(可以參考 controller/store/store.go#L250)
之後再由 Ingress Controller 的 Start 取出資料再放到 SyncQueue 裡面(可參考 controller/nginx.go#L359)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// New creates a new object store to be used in the ingress controller.
//
//nolint:gocyclo // Ignore function complexity error.
func New(
namespace string,
namespaceSelector labels.Selector,
configmap, tcp, udp, defaultSSLCertificate string,
resyncPeriod time.Duration,
client clientset.Interface,
updateCh *channels.RingChannel,
disableCatchAll bool,
deepInspector bool,
icConfig *ingressclass.Configuration,
disableSyncEvents bool,
) Storer {
ingEventHandler := cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
ing, _ := toIngress(obj)
if !watchedNamespace(ing.Namespace) {
return
}
ic, err := store.GetIngressClass(ing, icConfig)
if err != nil {
klog.InfoS("Ignoring ingress because of error while validating ingress class", "ingress", klog.KObj(ing), "error", err)
return
}
klog.InfoS("Found valid IngressClass", "ingress", klog.KObj(ing), "ingressclass", ic)
...
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// Start starts a new NGINX master process running in the foreground.
func (n *NGINXController) Start() {
for {
select {
case err := <-n.ngxErrCh:
if n.isShuttingDown {
return
}
// if the nginx master process dies, the workers continue to process requests
// until the failure of the configured livenessProbe and restart of the pod.
if process.IsRespawnIfRequired(err) {
return
}
case event := <-n.updateCh.Out():
if n.isShuttingDown {
break
}
if evt, ok := event.(store.Event); ok {
klog.V(3).InfoS("Event received", "type", evt.Type, "object", evt.Obj)
if evt.Type == store.ConfigurationEvent {
// TODO: is this necessary? Consider removing this special case
n.syncQueue.EnqueueTask(task.GetDummyObject("configmap-change"))
continue
}
n.syncQueue.EnqueueSkippableTask(evt.Obj)
} else {
klog.Warningf("Unexpected event type received %T", event)
}
case <-n.stopCh:
return
}
}
}
有關 Ring Buffer 可以參考 Goroutine 與 Channel 的共舞 | Shawn Hsu
有關 Informer 可以參考 Kubernetes 從零開始 - Informer 架構以及 Controller Pattern | Shawn Hsu
那這個 SyncQueue 在初始化的時候會給一個 callback 負責處理 queue 裡面的資料
以 Ingress Nginx Controller 來說,就是 syncIngress(controller/store.go#L908)
那設定檔最終會被交給 Nginx 內部並且 reload
Resource 的新增刪除更新某種程度上都會影響 reload 的頻率
比如說
Ingress被新增Ingress,Secrets,Services被刪除Ingress的內部路由規則,TLS 或者 annotation 有變化
等等的都會要 reload
如果你的 Ingress 是非法的,比如說打錯字之類的
為了避免無法正常運作,Admission Webhook 會被用於驗證,通過之後才會送到 Controller 進行處理
Downtime of Ingress Nginx Controller
那這個 reload 其實會造成問題
Nginx 的 reload 是透過新的 worker process 接替(新的連線都由他處理)
然後舊的 worker process 會被 graceful shutdown(i.e. 處理完當前的連接就會停止)
看起來不會造成 downtime?
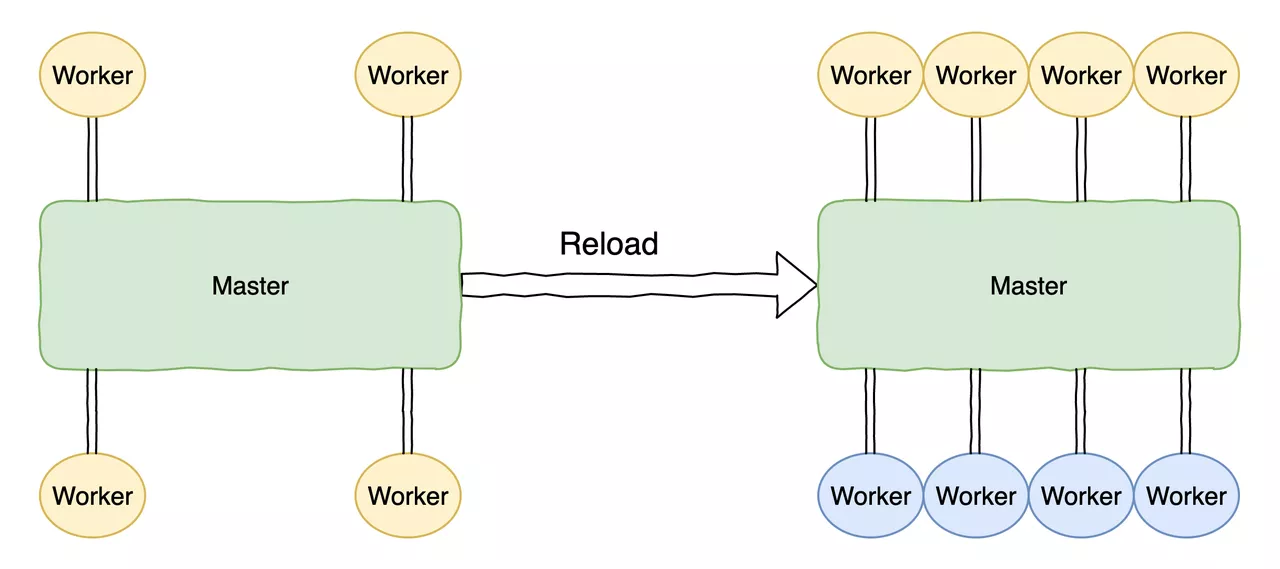
考慮到 keepalive 的長連接設定
因為 config 更新會造成 reload,Nginx 便會主動通知 connection 關閉
然而在系統負載過高的情況下,client 可能會沒收到關閉的通知,進一步造成 downtime
另一個點是,舊的 worker process 需要處理連接的時間其實是無法預測的
所以說如果你一直 trigger reload,old worker process 就會一直長出來,並且因為執行時間是無法預測的
進而導致 process 數量過多,提升系統壓力,進而導致 downtime 的出現
Traefik Ingress Controller
而 Traefik 就不會有 downtime 的問題,因為 Traefik 不需要將 configuration reload,然後再交給新的 worker process 去處理
所有的設定檔都是 in-memory 進行 hot reload 的
整體的實作也同樣是基於 Informer 的衍伸架構
有關 Informer 可以參考 Kubernetes 從零開始 - Informer 架構以及 Controller Pattern | Shawn Hsu
監聽 Ingress Resource 的變化是使用 WatchAll 這個 function 註冊 EventHandler(可以參考 ingress/client.go#L141)
並且透過 eventCh 的 Golang channel 接收 event
有關 Golang channel 可以參考 Goroutine 與 Channel 的共舞 | Shawn Hsu
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
const (
resyncPeriod = 10 * time.Minute
defaultTimeout = 5 * time.Second
)
// WatchAll starts namespace-specific controllers for all relevant kinds.
func (c *clientWrapper) WatchAll(namespaces []string, stopCh <-chan struct{}) (<-chan interface{}, error) {
eventCh := make(chan interface{}, 1)
eventHandler := &k8s.ResourceEventHandler{Ev: eventCh}
...
factoryIngress := kinformers.NewSharedInformerFactoryWithOptions(c.clientset, resyncPeriod, kinformers.WithNamespace(ns), kinformers.WithTweakListOptions(matchesLabelSelector))
_, err := factoryIngress.Networking().V1().Ingresses().Informer().AddEventHandler(eventHandler)
if err != nil {
return nil, err
}
...
}
這個 eventCh 的資料會被 Provide 的 function 接收並處理
初步來看,會讀取 Ingress Resource 的資料並且計算 hash 值,只有在不同的 hash 值才會進行下一步
下一步會被進一步送到 configurationChan 裡面(可以參考 ingress/kubernetes.go#L136)
eventCh 是一個 Ring Buffer(code 裡面稱為 RingChannel),可以參考 aggregator/ring_channel.go
有關 Ring Buffer 可以參考 Goroutine 與 Channel 的共舞 | Shawn Hsu
所有的 Provider 都是被 Provider Aggregator 所管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
// Provide allows the k8s provider to provide configurations to traefik
// using the given configuration channel.
func (p *Provider) Provide(configurationChan chan<- dynamic.Message, pool *safe.Pool) error {
logger := log.With().Str(logs.ProviderName, "kubernetes").Logger()
ctxLog := logger.WithContext(context.Background())
k8sClient, err := p.newK8sClient(ctxLog)
if err != nil {
return err
}
if p.AllowExternalNameServices {
logger.Info().Msg("ExternalName service loading is enabled, please ensure that this is expected (see AllowExternalNameServices option)")
}
pool.GoCtx(func(ctxPool context.Context) {
operation := func() error {
eventsChan, err := k8sClient.WatchAll(p.Namespaces, ctxPool.Done())
if err != nil {
logger.Error().Err(err).Msg("Error watching kubernetes events")
timer := time.NewTimer(1 * time.Second)
select {
case <-timer.C:
return err
case <-ctxPool.Done():
return nil
}
}
throttleDuration := time.Duration(p.ThrottleDuration)
throttledChan := throttleEvents(ctxLog, throttleDuration, pool, eventsChan)
if throttledChan != nil {
eventsChan = throttledChan
}
for {
select {
case <-ctxPool.Done():
return nil
case event := <-eventsChan:
// Note that event is the *first* event that came in during this
// throttling interval -- if we're hitting our throttle, we may have
// dropped events. This is fine, because we don't treat different
// event types differently. But if we do in the future, we'll need to
// track more information about the dropped events.
conf := p.loadConfigurationFromIngresses(ctxLog, k8sClient)
confHash, err := hashstructure.Hash(conf, nil)
switch {
case err != nil:
logger.Error().Msg("Unable to hash the configuration")
case p.lastConfiguration.Get() == confHash:
logger.Debug().Msgf("Skipping Kubernetes event kind %T", event)
default:
p.lastConfiguration.Set(confHash)
configurationChan <- dynamic.Message{
ProviderName: "kubernetes",
Configuration: conf,
}
}
// If we're throttling, we sleep here for the throttle duration to
// enforce that we don't refresh faster than our throttle. time.Sleep
// returns immediately if p.ThrottleDuration is 0 (no throttle).
time.Sleep(throttleDuration)
}
}
}
notify := func(err error, time time.Duration) {
logger.Error().Err(err).Msgf("Provider error, retrying in %s", time)
}
err := backoff.RetryNotify(safe.OperationWithRecover(operation), backoff.WithContext(job.NewBackOff(backoff.NewExponentialBackOff()), ctxPool), notify)
if err != nil {
logger.Error().Err(err).Msg("Cannot retrieve data")
}
})
return nil
}
那,是誰 consume configurationChan 呢?
主程式 traefik 會在啟動的時候初始化 ConfigurationWatcher(可參考 cmd/traefik/traefik.go#L313)
同時 configurationChan 也是在 ConfigurationWatcher 裡面被建立以及被提供給 Provider Aggregator 使用
1
2
3
4
5
6
7
8
9
10
func (c *ConfigurationWatcher) startProviderAggregator() {
log.Info().Msgf("Starting provider aggregator %T", c.providerAggregator)
safe.Go(func() {
err := c.providerAggregator.Provide(c.allProvidersConfigs, c.routinesPool)
if err != nil {
log.Error().Err(err).Msgf("Error starting provider aggregator %T", c.providerAggregator)
}
})
}
真正的魔法發生在 receiveConfigurations 以及 applyConfigurations 裡面
ConfigurationWatcher 裡面有兩個 channel,分別是 allProvidersConfigs 以及 newConfigs
receiveConfigurations 負責從 allProvidersConfigs 接收資料,並且進行處理
然後再將資料送到 newConfigs 裡面,被 applyConfigurations 所使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
// receiveConfigurations receives configuration changes from the providers.
// The configuration message then gets passed along a series of check, notably
// to verify that, for a given provider, the configuration that was just received
// is at least different from the previously received one.
// The full set of configurations is then sent to the throttling goroutine,
// (throttleAndApplyConfigurations) via a RingChannel, which ensures that we can
// constantly send in a non-blocking way to the throttling goroutine the last
// global state we are aware of.
func (c *ConfigurationWatcher) receiveConfigurations(ctx context.Context) {
newConfigurations := make(dynamic.Configurations)
var output chan dynamic.Configurations
for {
select {
case <-ctx.Done():
return
// DeepCopy is necessary because newConfigurations gets modified later by the consumer of c.newConfigs
case output <- newConfigurations.DeepCopy():
output = nil
default:
select {
case <-ctx.Done():
return
case configMsg, ok := <-c.allProvidersConfigs:
if !ok {
return
}
logger := log.Ctx(ctx).With().Str(logs.ProviderName, configMsg.ProviderName).Logger()
if configMsg.Configuration == nil {
logger.Debug().Msg("Skipping nil configuration")
continue
}
if isEmptyConfiguration(configMsg.Configuration) {
logger.Debug().Msg("Skipping empty configuration")
continue
}
logConfiguration(logger, configMsg)
if reflect.DeepEqual(newConfigurations[configMsg.ProviderName], configMsg.Configuration) {
// no change, do nothing
logger.Debug().Msg("Skipping unchanged configuration")
continue
}
newConfigurations[configMsg.ProviderName] = configMsg.Configuration.DeepCopy()
output = c.newConfigs
// DeepCopy is necessary because newConfigurations gets modified later by the consumer of c.newConfigs
case output <- newConfigurations.DeepCopy():
output = nil
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// applyConfigurations blocks on a RingChannel that receives the new
// set of configurations that is compiled and sent by receiveConfigurations as soon
// as a provider change occurs. If the new set is different from the previous set
// that had been applied, the new set is applied, and we sleep for a while before
// listening on the channel again.
func (c *ConfigurationWatcher) applyConfigurations(ctx context.Context) {
var lastConfigurations dynamic.Configurations
for {
select {
case <-ctx.Done():
return
case newConfigs, ok := <-c.newConfigs:
if !ok {
return
}
// We wait for first configuration of the required provider before applying configurations.
if _, ok := newConfigs[c.requiredProvider]; c.requiredProvider != "" && !ok {
continue
}
if reflect.DeepEqual(newConfigs, lastConfigurations) {
continue
}
conf := mergeConfiguration(newConfigs.DeepCopy(), c.defaultEntryPoints)
conf = applyModel(conf)
for _, listener := range c.configurationListeners {
listener(conf)
}
lastConfigurations = newConfigs
}
}
}
Apache APISIX Ingress Controller
與 Ingress Nginx Controller 以及 Traefik Ingress Controller 不同的是
APISIX 他的設定檔是存放在 etcd 裡面,而不是直接 in-memory
Traefik Enterprise 則是由 Control Plane 負責推播所有資料(包含 events, certificates 以及 Traefik 設定檔等等),跟 Traefik OSS 的實作是不同的
這些資料是存放在 distributed 的 key-value store 裡面
Apache APISIX 本身是為了解決 Ingress Nginx Controller 的 reload 問題而誕生的
而實作上是基於 Nginx 以及 LuaJIT(OpenResty)
透過將動態路由的設定檔置於 APISIX Core 中,所有的 request 都會先經過 Nginx 的單點入口,再經過 APISIX Core 動態的指定 upstream(i.e. 你的後端),從而避免 Nginx reload 帶來的影響
也因為 APISIX 本人與 etcd 都支援多點部署,單點失效並不會影響整體 proxy 的運作
APISIX 內,Nginx 只會有一個 server 一個 location
所以不管 APISIX Core 怎麼變化,Nginx 都不需要 reload
Ingress Controller to Support Gateway API
Ingress 的 Resource 的設計是很粗略的
除了缺少比較進階的功能之外,他也沒辦法進行擴充,移植性也很差
如果更換 Controller,Ingress 大概率無法重複利用
比方說 Ingress Nginx Controller 會透過自定義的 annotation 來達到特殊的功能
如果你換成 Traefik Ingress Controller,那這個 annotation 就無法使用
每一家都有他自己特殊的設定檔,其實是會造成混亂
比較好的做法是例如說 L4 routing 這種比較常見的設定應該是由 Resource 來管理,而非依靠 Controller 自己的實作,所以 標準化是必要的
而且 Ingress 需要開發者知道不同底層的設定與實作(例如 Ingress Nginx Controller 需要使用這個 annotation 達到某某功能而其他的則是另一個)
身為 Application Developer 的我們其實根本不需要知道這些
於是 Kubernetes 想要利用新的 API 來達到
- 更細緻的控制(L4 routing, TLS … etc.)
- 提供標準化的接口(避免 vendor lock-in)
- Policy 權責分離
稱之為 Gateway API
Gateway API
但 Gateway API 其實一個統稱,他包含多個 Resource 如 GatewayClass, Gateway, HTTPRoute 以及 GRPCRoute
分成不同的 Resource 其實是對應到不同的角色(權責分離)
Route
比如說身為應用程式開發者的我們其實比較在乎的是 HTTPRoute 以及 GRPCRoute 等等的
底層要用什麼來實現(Ingress Nginx Controller 或者 Traefik Ingress Controller)其實對我們來說沒差
反正他會動就好了嘛
我只在乎,/foo 要導向 whoami 這個 service 的 80 port
這才是重點
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: http-app
namespace: default
spec:
parentRefs:
- name: my-gateway
hostnames:
- whoami
rules:
- matches:
- path:
type: Exact
value: /foo
backendRefs:
- name: whoami
port: 80
GatewayClass
那誰會在乎要底層用什麼來實現呢?
肯定是管理 cluster 的人
比方說我想要使用 traefik.io/gateway-controller
1
2
3
4
5
6
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: my-gateway-class
spec:
controllerName: traefik.io/gateway-controller
Gateway
你指定了 Route,選定了 Ingress Controller(GatewayClass)
其實還有一個東西要指定,是進入集群的入口
這個設定有點陌生
如果回顧 From Service to Ingress Controller 的時候,你會發現
即使在 Ingress Resource 裡面也沒有相對應的東西啊?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
那這個集群的入口是什麼東西呢?
你沒看到的原因在於 Ingress Controller 其實幫你做掉了
舉 Ingress Nginx Controller 為例,根據 Basic usage - host based routing
On many cloud providers ingress-nginx will also create the corresponding Load Balancer resource.
All you have to do is get the external IP and add a DNS A record inside your DNS provider that point myservicea.foo.org and myserviceb.foo.org to the nginx external IP.
從上述你可以很清楚的看到說,所有的流量會先進到 Load Balancer Resource
所以入口就是這個東西
如果以新的 API 來實作就是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: my-gateway
spec:
gatewayClassName: my-gateway-class
listeners:
- name: https
protocol: HTTPS
port: 443
tls:
certificateRefs:
- kind: Secret
name: mysecret
Put it All Together
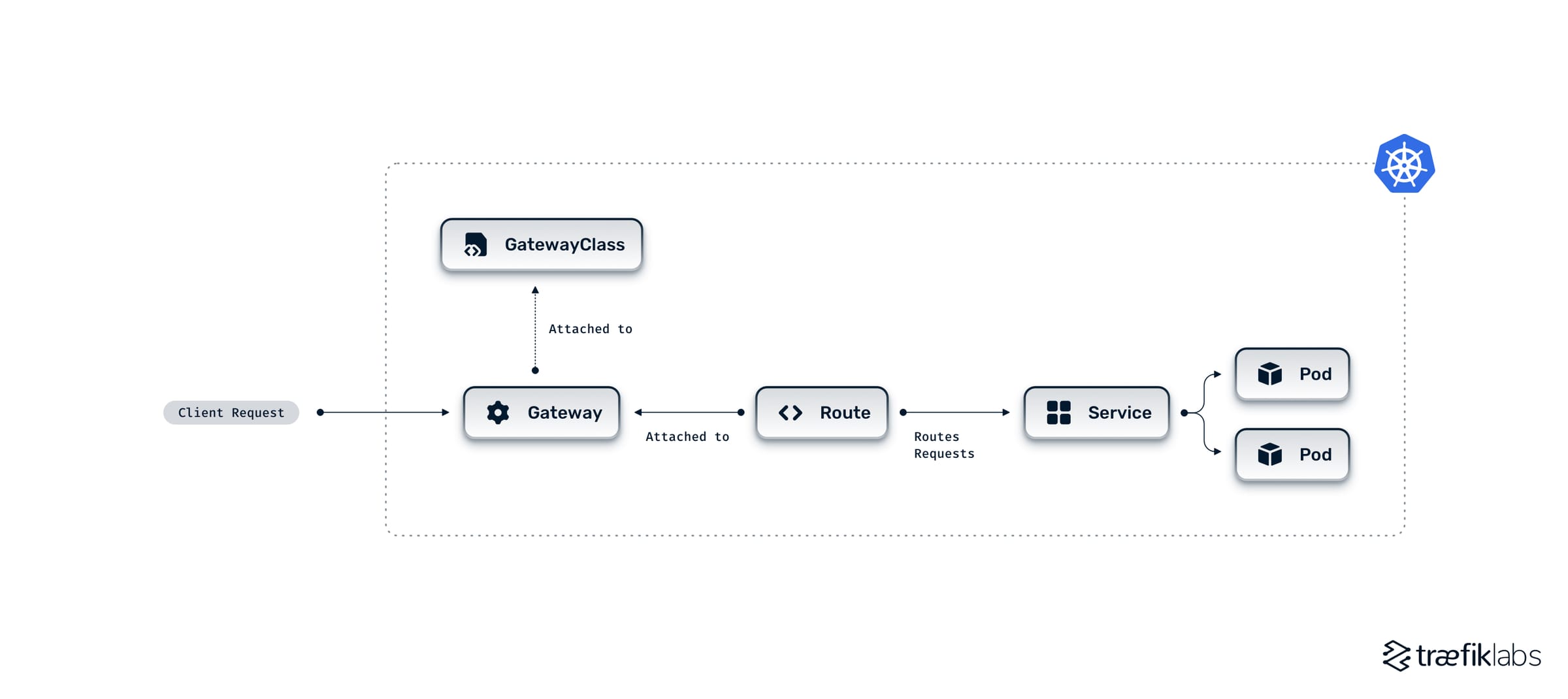
ref: Kubernetes Gateway API: What Is It and Why Do You Need It?
你可以看到說,Gateway API 實際上是將每個東西都拆得很開
根據不同的角色,各自維護他們所關心的東西
Cluster Admin負責決定要使用哪一個 Ingress Controller 並指定於 GatewayClassDevops Team負責管理集群的入口並指定於 GatewayApplication Developer負責管理路由規則並指定於 Route
以前的 Ingress 把所有東西都放在一起
他沒辦法很好的做到權責分離,Application Developer 只需要改一個 route
但卻需要取得完整的設定檔,他有可能去動到其他東西,進而造成不必要的錯誤
Adoption of Gateway API
身為 Ingress 的後繼者,Gateway API 的進度卻不盡人意
雖然新的標準立意良善並且修正了許多缺點,但一次性的 migration 是必須的
俗話說的好,會動就不要動它,很顯然的這些優點並沒有說服開發者們進行升級
並且也不是現有的 Ingress Controller 都支援 Gateway API
舉例來說,Ingress Nginx Controller 不支援 Gateway API(可參考 ⚠️ Ingress NGINX Project Status Update ⚠️)
取而代之的是一個新的專案 kubernetes-sigs/ingate
更換新的 Ingress Controller 除了要升級 Ingress 到 Gateway API 之外
Controller 的穩定性也是需要考慮的
種種原因之下導致現在 Gateway API 的採用率並不高
References
- Round Robin Load Balancing Definition
- DNS for Services and Pods
- Service
- EndpointSlices
- Ingress
- Ingress controller V Gateway API
- I’m a newb to Kubernetes. Why do I need NGINX/Traefic/etc. ingress controllers?
- How it works
- How nginx reload work ? why it is zero-downtime
- https://nginx.org/en/docs/control.html
- 为什么 NGINX 的 reload 不是热加载?
- Why do you need Apache APISIX when you have NGINX and Kong?
- Concepts
- 为什么 Apache APISIX 选择 NGINX+Lua 技术栈?
- Ingress controller V Gateway API
- Kubernetes Gateway API: What Is It and Why Do You Need It?
- Basic usage - host based routing
- Gateway API
- ⚠️ Ingress NGINX Project Status Update ⚠️
- 負載平衡演算法類型
- 什麼是負載平衡?
Leave a comment