資料庫 - 從 Netflix 的 Tudum 系統看分散式系統中那些 Read/Write 問題
Data Consistency
Eventually Consistent
在分散式系統中,根據 CAP Theorem 我們知道
AP 系統,沒辦法保證所有節點在收到相同的資料的時候維持一致(因為還沒同步完成)
所以這類系統提供的保證通常都是 Eventually Consistent
也就是他最終會趨於一致,只是時間不好說
也因此這個保證是非常弱的
那最強的保證是什麼? 是 Strong Consistency
強一致性的系統(又稱 可線性化的系統),在高階角度看下來就好像只有一個資料副本,並且所有的操作都是 Atomic 的
也就是說他並不會出現一些奇奇怪怪的狀況,例如說寫進去的資料過一段時間才出來之類的(近新保證)
一個可線性化的系統(i.e. 強一致性),本身就會提供近新保證
單台資料庫並不一定可以線性化,要看隔離機制
比如說 snapshot isolation 不能保證 linearizability,因為 snapshot 不能讀到比他新的資料
有關 isolation 的介紹,可以參考 資料庫 - Transaction 與 Isolation | Shawn Hsu
但是,最終一致性與強一致性,跨距太遠了
我們需要有一些介於兩者之間的保證,如 Read-after-Write, Monotonic Read, Sequential Consistency, Same Prefix Read
這些都在一定程度上保證了資料的一致性
Read-after-Write Consistency
一個常見的問題是,我寫入的資料,我馬上讀取,卻讀不到
而原因在於你寫入與讀取的 replica 可能是不同台機器,資料還沒有同步這麼快
對於使用者來說這無疑是很奇怪的,我應該要能夠看到我剛剛做的改變
Read-after-Write 保證了,你寫入的資料,你馬上讀取,就會讀到
但是對於別人的資料,就無法保證
解法可以針對自己的資料,讓他讀取 leader 的 replica,這樣就保證不會有未同步的問題
缺點是當讀取自己的資料量大的時候,速度就會變慢了
Monotonic Read
更糟糕的是,如果多次查詢,返回的結果不一致,這可能比查不到還要糟糕
比如說,你查詢一個商品的庫存,第一次查詢是 10,第二次查詢是 0,第三次又是 10
那他到底是有還是沒有? 這種 時間倒流的現象 是 Monotonic Read 想要避免的問題
問題同樣也在讀取不同的 replica 資料同步問題
解決的辦法也滿簡單的,你只要確保,該 user 的所有 request 都是由同一個 replica 處理就好了
比如說用 hash function 將特定的使用者全部導向特定的機器上
稱之為 Monotonic read
為什麼叫做單調讀取? 因為當你讀了新的資料,就保證不會讀到舊的
問題是出在讀取不同的 replica 資料,那解法很自然就是讀取相同的 replica
Sequential Consistency
也同樣是順序,不同的是 Monotonic Read 是只保證 你 不會讀到舊的資料
而 Sequential Consistency 是保證全部的節點的資料都會有相同的順序
Same Prefix Read
假設資料有順序性或者說因果關係
讀取不同 replica 的資料,也同樣是遇到同步問題,導致使用者會看到牛頭不對馬尾的資料
比如說留言板,留言的順序是有因果關係/時間關係的
資料時間 與 資料寫入時間 的順序不一定是一樣的
一樣是因為讀取不同 replica 資料造成的
解法可以讀取相同的 replica, 或者是依靠時間戳記,但時間並不可靠,可參考 Unreliable Clock
Netflix Raw Hollow System for Tudum
Netflix 的 Tudum 網站提供了一些獨家專訪,花絮以及特別收錄的內容
讓使用者可以更深層的探索他們最喜歡的影視作品
這個系統主要的角色就是 內容編輯者 以及 檢視者(使用者)
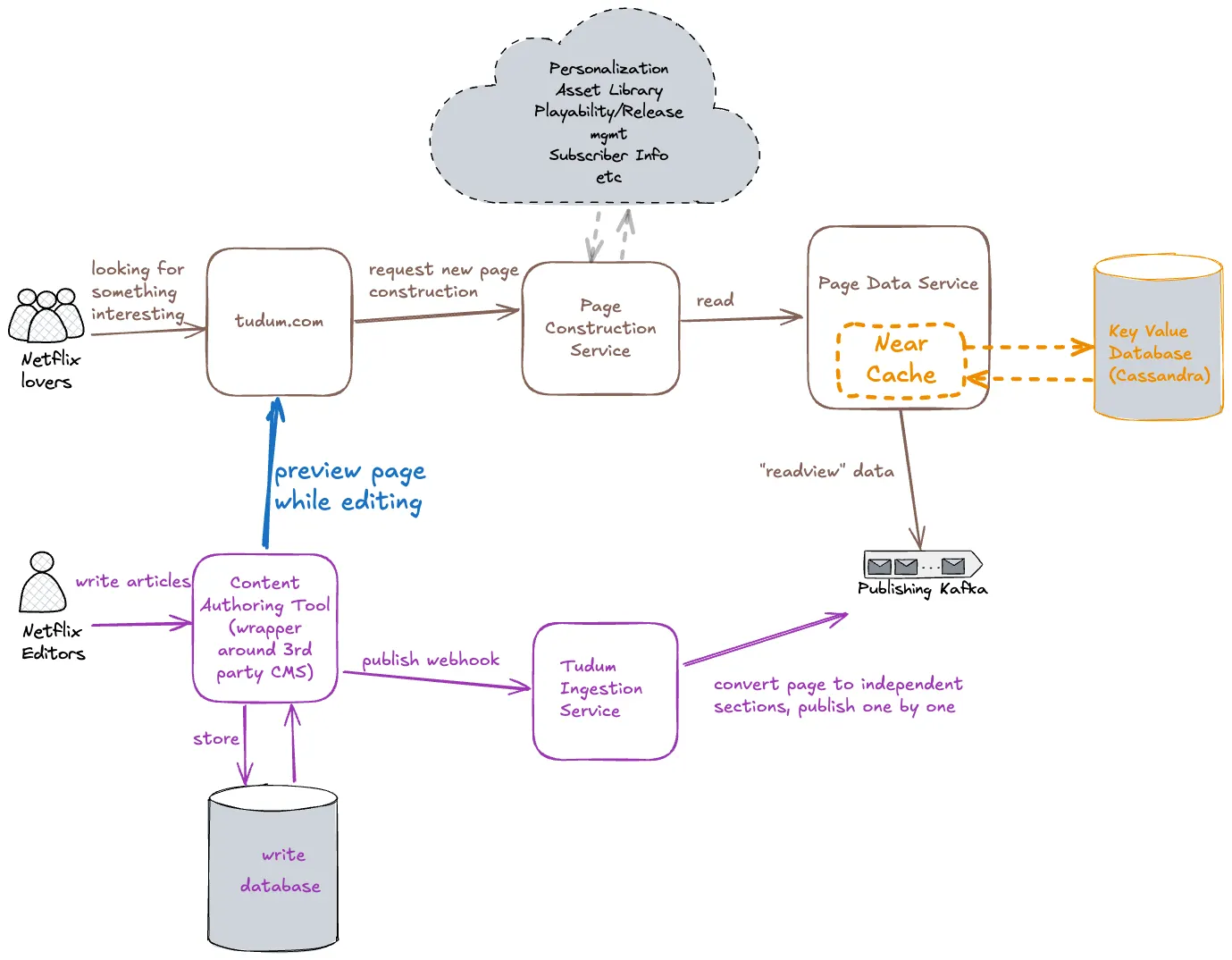
ref: Netflix Tudum Architecture: from CQRS with Kafka to CQRS with RAW Hollow
一開始是由編輯者編輯一些有趣的內容比如說花絮照片等等
透過他發布到 CMS 系統內做儲存,同時也同步到 Ingestion 服務拆解內容並轉換成讀取優化的資料(原因在於這些內容需要根據不同使用者做客製化),透過 Kafka 發布進一步處理,並儲存在一個獨立的高可用性的資料庫內
每當使用者查看內容的時候,Page Data Service 會讀取這些拆解過後的資料,重組成客製化的資料並呈現給使用者看
為了更快速的處理資料,internal cache 的方案被採用,為了降低從資料庫讀取的時間
有關 kafka 可以參考 資料庫 - 從 Apache Kafka 認識 Message Queue | Shawn Hsu
這個系統可以很好的工作,讀寫分離讓他可以很輕鬆的擴展
非同步的資料處理也可以很好的使系統達到高可用性
架構上屬於 Event driven
你可以看得出來,非同步的方式意味著這個系統是提供 Eventual Consistency 的保證
而 Netflix 團隊發現到,他們犧牲了能快速預覽內容的方便性,即使該系統提供了足高的可用性
Page Data Service 為了能夠更快速的取得資料,其內部擁有 near cache 的機制
這個內部的 near cache 可以在背景執行同步更新,每隔一段 refresh cycle 資料就會從 KVDAL(Key Value Data Abstraction Layer) 同步
那他造成的問題就會是,當資料量大起來的時候,使用者會看到過期的資料
也就是說目前 Event Driven 的架構是沒有近新保證的
Raw Hollow System
為了解決這種近新保證的問題,Netflix 團隊開發了 Raw Hollow(Read After Write Hollow) System
Raw Hollow 加強了 Hollow 系統
系統如其名,他擁有 Read-after-Write 的近新保證,並且允許更新 near cache 的資料
Raw Hollow 也自動滿足 Eventual Consistency 的保證(因為它提供了 Read-after-Write 的保證)
Architecture
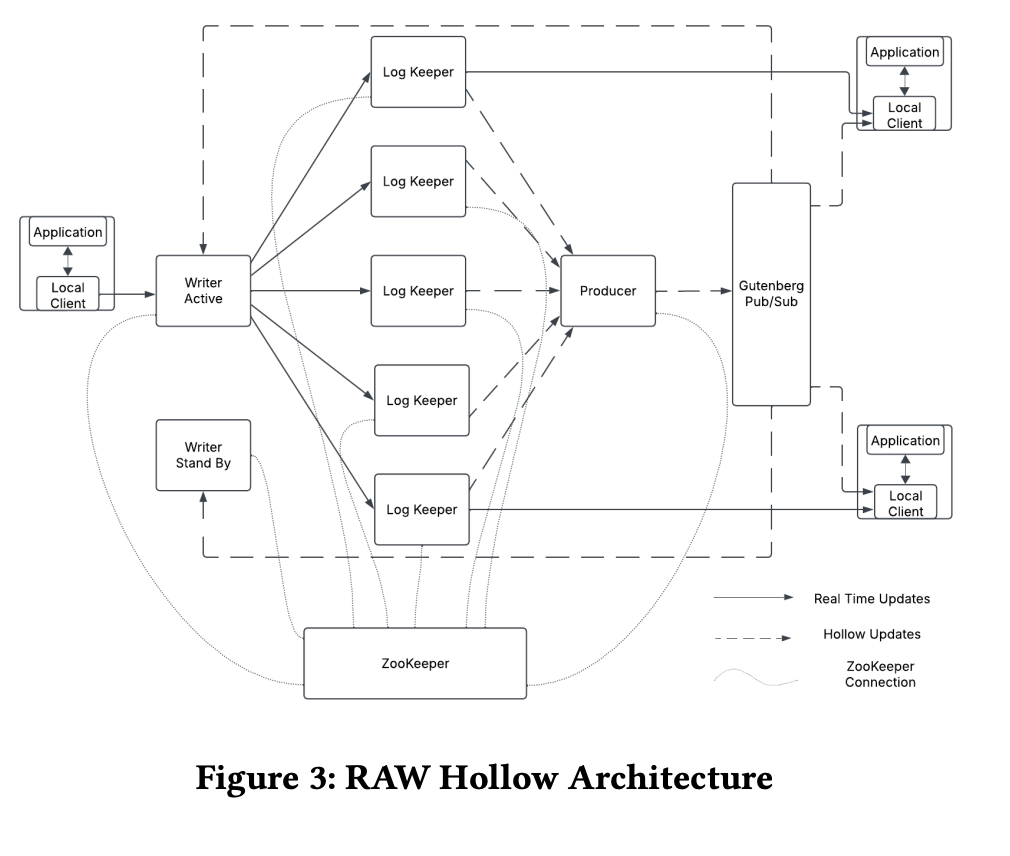
架構上你可以看到,與 Hollow 系統不同的是,source of truth 不見了
意味著任何 local client 都可以透過 writer 更新 near cache 的資料
整個系統的資料包含了兩個部分
- base dataset
- in-flight changes(還沒被正式寫入的資料)
角色的部分
-
writer: 負責處理寫入資料(single leader 可參考 資料庫 - 初探分散式資料庫 | Shawn Hsu) -
local client: 負責處理讀取資料 -
producer: 負責推播新的資料(非完整 dataset, 僅包含差異資料) -
logkeeper: 儲存資料的暫存的地方,1GB 大小的 circular log
整體的操作圍繞在 base dataset 之上
每個 local client 都可以更新 base dataset 的資料
他們需要透過發送 request 到 writer 來更新
writer 也具備高可用性(使用 ZooKeeper 來協調),同一時間只有一個 writer 負責寫入
當他意外下線,其他 hot standby writer 會接手
資料會暫時的儲存在 logkeeper 內
writer 會將資料同步至多個 logkeeper 內,直到所有 Quorum 內的 logkeeper 都擁有資料
才會視為操作成功
後續 producer 將會從 logkeeper 取得資料,計算差異化資料並推播至 local client 身上
Writer Self Healing
writer 會等待 所有 Quorum 內的 logkeeper 都擁有資料 才會視為操作成功
所以如果寫到一半, 即使 writer 掛掉,部分 logkeeper 內還是會有暫存資料對吧
所以新的 leader 上位,他需要跟所有 Quorum 內的 logkeeper 取得 in-flight changes 的資料
最大化的避免 data loss
如果所有 logkeeper 都掛了呢?
producer 每隔 30 秒就會上傳完整的 in-flight changes 至 S3
即使全掛,資料損失也降到最低,對於 Netflix 來說,這樣的損失是可以接受的
Constantly up-to-date
你說,透過 pub/sub 接收推播資料,這也有延遲不是
因此,為了能夠極大化的接收到最新 base dataset 的資料
local client 其實會偷跑
我們說 Raw Hollow 資料由 base dataset 以及 in-flight changes 組成
除了 pub/sub 過來的 base dataset 以外
local client 會嘗試透過 Long Polling 的機制將處理中的 in-flight changes 同步過來
有關 Long Polling 可以參考 淺談 Polling, Long Polling 以及其他即時通訊方法論
那如果 logkeeper Quorum 不滿足怎麼辦
Quorum 會動態調整,使得 Quorum 內的 logkeeper 始終 Strongly Consistent
Hollow System
Hollow 是一個分散式的 in-memory near cache 的系統,透過將資料壓縮至記憶體內,並允許應用程式快速的讀取
透過讀取 source of truth 的資料,透過 pub/sub 的機制同步到不同的節點上
注意到,Hollow 系統是一個 read-only 的系統,它只允許讀取資料,不允許寫入(或者說更改)資料
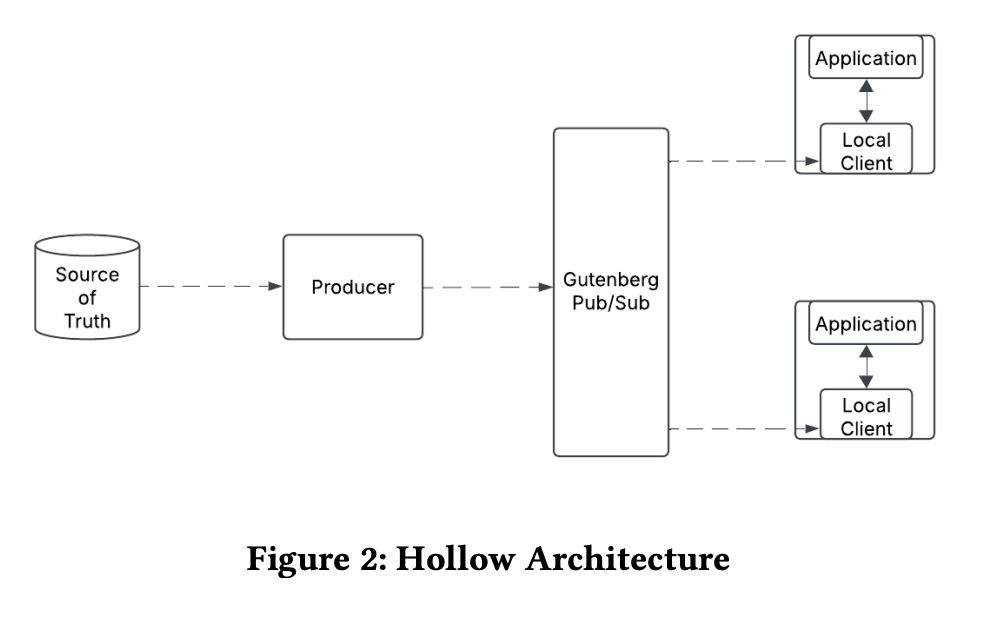
Adoption of Raw Hollow System
乍看之下 Raw Hollow 好像跟原本的 near cache 沒什麼兩樣
但要注意的是 Raw Hollow 系統內部儲存的是 “完整的資料集”(被壓縮過)
他本質上是資料庫而非 cache
而 Raw Hollow 系統帶來了以下的好處
- 每個節點可以儲存高達
1 億筆資料,因為壓縮的資料使得整個資料集可以載入記憶體當中 - 快速的存取資料,減少 I/O 的消耗
- 減少了資料傳遞的等待時間
最終的 Tudum 架構如下
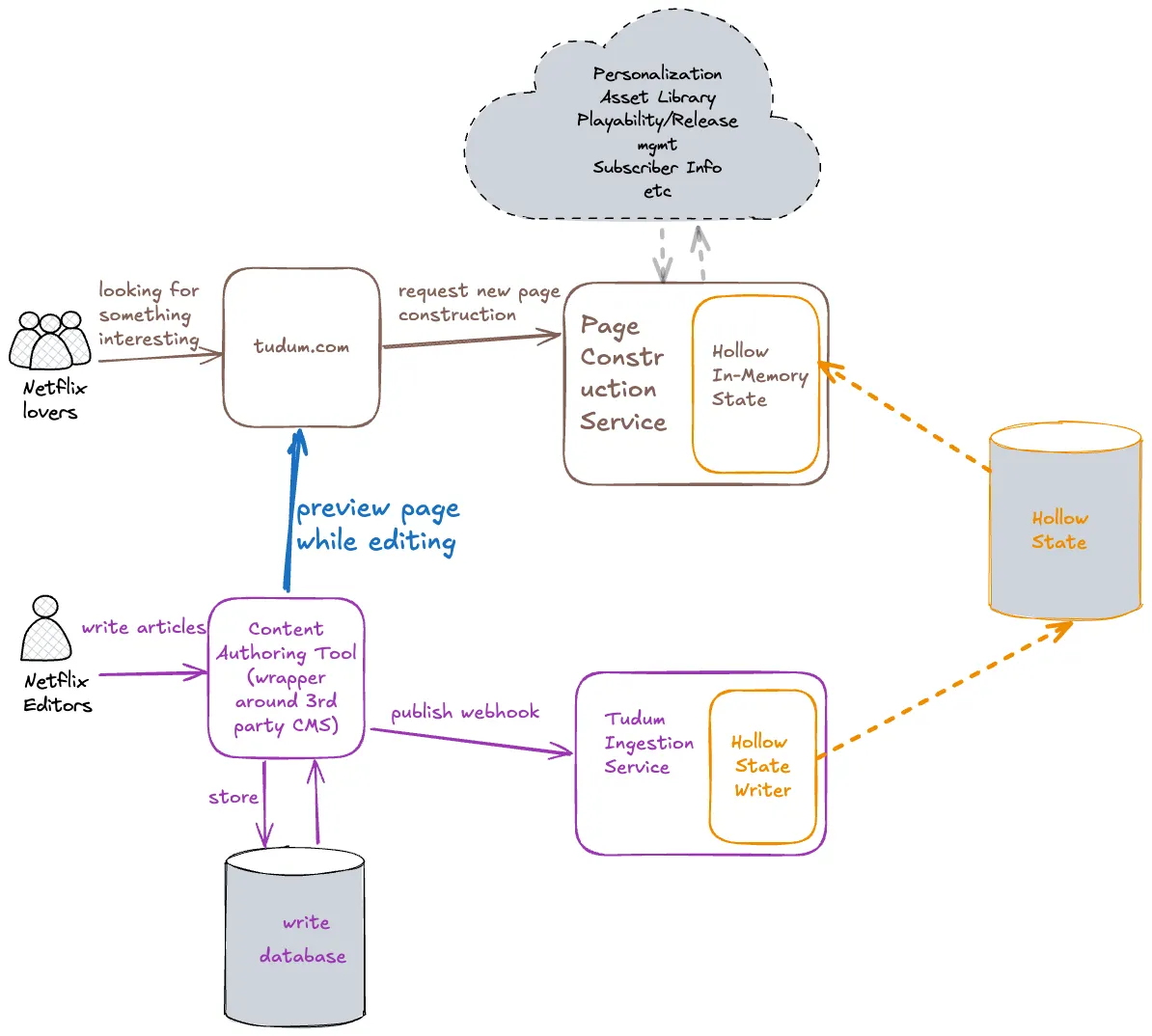
ref: Netflix Tudum Architecture: from CQRS with Kafka to CQRS with RAW Hollow
Read/Write Phenomena
單一節點的讀寫異常,我們在 資料庫 - Transaction 與 Isolation | Shawn Hsu 已經看了滿多的
但在分散式系統中,事情更複雜了,尤其是在 multi-leader 以及 leaderless replication 的情況下
雖然 multi leader 會增加系統的複雜度
但是在某些情況下,multi leader 會是一個不錯的選擇
single leader 因為每個 partition 只能有一個 leader,所以所有寫入都必須要經過他
這顯然在某些情況下會增加延遲,這並不是我們想看到的
但要怎麼處理 multi leader 帶來的衝突問題?
以我們熟知的版本控制工具 git 來說,通常是我們要手動處理衝突
分散式系統下,不是不行啦 但我們有更好的方法
Causality and Ordering
要解決衝突的問題,需要先確定資料相互之間的關係
因果關係 與 事件的順序關係 是不同的概念
對可線性化的系統而言,兩者是等價的
不過分散式系統下會變得複雜
每個事件到達節點的速度是不同的
有可能造成明明是 A ![]() B,卻因為網路延遲等問題
B,卻因為網路延遲等問題
變成 B ![]() A
A
這時候,節點收到的順序關係為 B ![]() A
A
但是真正的因果關係為 A ![]() B
B
很明顯這不對,因此可以利用 Lamport Timestamp 或者 Version Vector 來確定因果關係
Lamport Timestamp
既然用絕對時間會有誤差(事件抵達的時間不一定代表因果關係),我能不能使用類似的方法
使用一個單調遞增的數字表示事件的先後順序,數字小的先發生,數字大的後發生(i.e. logical clock)
Lamport Timestamp 是類似的概念
他由 (node id, counter) 所組成
counter 就是那個單調遞增的數字,針對每一次對 x 的操作我都 counter++
這樣一來,藉由排序 counter 我就可以知道事件的先後順序,也知道是誰做的改變(根據 node id)
遇到衝突的時候
只要找到最小的 counter 就是最早發生的事件,就可以以它為準
也因為該 timestamp 有 node id 的資訊,你也知道資料該從哪裡拿
看似美好但執行起來會有點小問題
因為 Lamport Timestamp 是存在在廣大的叢集裡面
要知道順序,唯一的辦法只有從系統當中收集所有資訊才能判斷
也因此他所花費的時間很多,況且萬一其中一個節點掛掉,你就很難找到真正最早發生的事件
並且 Lamport Timestamp 無法確認 並發 的狀況
因為事件都是用 counter 來表示,是單調遞增的,它只能確定因果關係
Version Vector
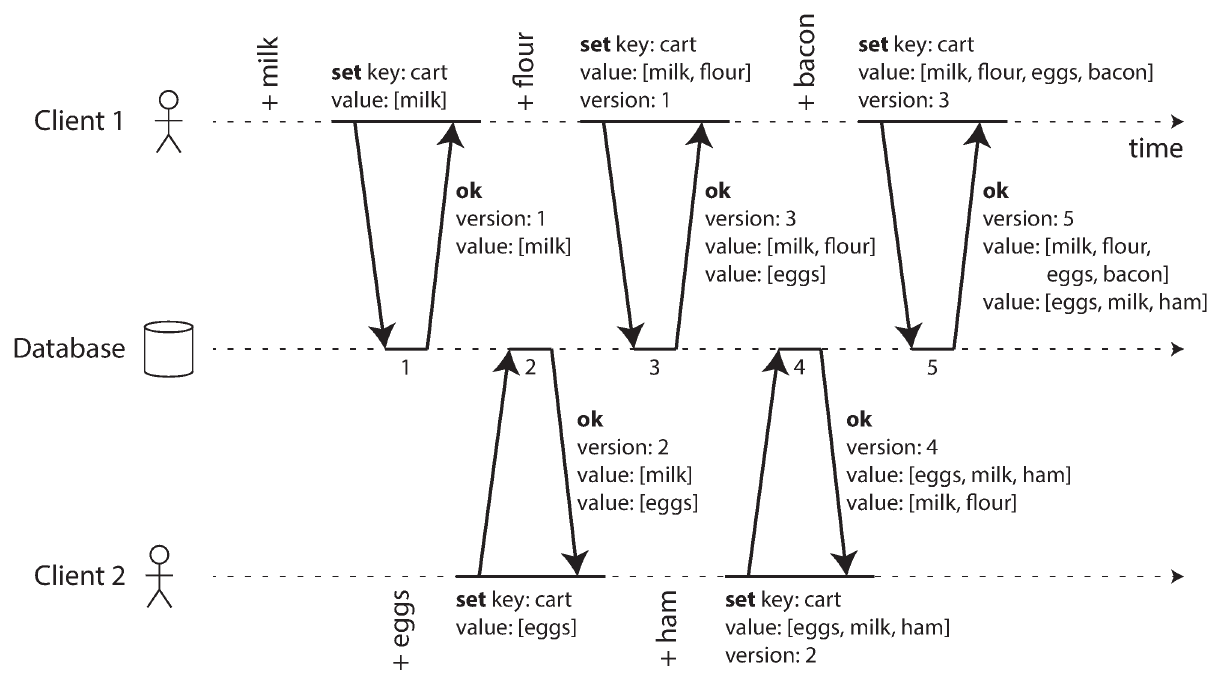
ref: 《Designing Data-Intensive Applications》ch 5—Replication
簡單來說,就是替每個 key 維護一個版本號
藉由版本號,系統可以知道依賴關係(注意到不是順序關係)
比對版本號,你可以知道淺在的衝突,但 version vector 本身 並沒有辦法解決衝突
他只是會儲存所有已經寫入的資料,並提供一個機制讓你可以知道這些資料的因果關係
注意到他跟 vector clock 不是一個東西
vector clock 是用於確認事件的先後關係
version vector 是用於確認資料的因果關係(使用者發文前必須要有帳號)
也可以使用 logical clock(單調遞增的計數器) 來達到類似的效果
Conflict Resolutions and Prevention
Last Write Wins
把最後一筆寫入的資料當成是正確的資料是一種做法
但是分散式系統下,每一台機器的時間可能會有誤差,幾毫秒甚至幾秒,這些誤差會導致你無法判斷誰是最後一個寫入的
時間戳記不一定代表事件的先後順序,可參考 Causality and Ordering
刪除舊的資料這件事情並不會收到任何的通知
所以在別的節點看來會有部分資料神秘地消失了
除此之外,Last Write Wins 無法判斷事件的先後順序
順序寫入 與 並發(concurrent) 在時間上的表示都是類似的
所以你會需要額外的機制判斷資料的因果關係(如 Lamport Timestamp 或 Version Vector)
並發是兩個事件是獨立的,互不干擾沒有因果關係
為了避免資料被安靜的刪除
如 Cassandra 推薦每個寫入 assign 一個 UUID
MVCC(Multi-Version Concurrency Control)
如果要徹底的防範衝突,使用 Transaction 是最佳的選擇
如果多個交易對相同資料進行改動,最終只有一個會成功
Transaction 底層實現實際上就是依靠 MVCC
每個 transaction 交易期間需要查看不同時間的的資料狀態
為了因應這種需求,不同時間點的資料的狀態需要被記錄下來
而這種技術稱之為 MVCC(Multi-Version Concurrency Control)
如果遇到同時寫入相同的資料,只有一個會成功其他失敗(i.e. optimistic locking)
如果是多個人讀取相同資料,其實不需要 lock(也就是寫入不擋讀取,讀取不擋寫入)
這樣可以最大化的提昇系統效能
有關 optimistic locking 的介紹,可以參考 資料庫 - Transaction 與 Isolation | Shawn Hsu
所以其實是依靠 Transaction 與 MVCC 共同實現的
Atomic Broadcast
MVCC 確保在寫入的狀況下可以保證一致性
這是基於被 snapshot 的資料順序是正確的
可是 MVCC 本身沒有保證資料順序是正確的阿? 它只能解決衝突問題
順序的解法如 Causality and Ordering 提到的,可以使用 Lamport Timestamp 或 Version Vector 來確定因果關係
不過那都是事後論的,並且有些仍然自動修復
既然問題在傳遞到各個節點的延遲導致的順序不一致
那是不是
- 確保每個更新都可以正確的傳遞到每個節點,全部都收到或是全部都沒收到
- 每個更新都嚴格按照順序進行傳遞
就能夠解決 Causality and Ordering 提到的問題
而這就是 Atomic Broadcast 的概念
如果更新沒收到要怎麼辦? 那簡單阿重試就好了
如果收到 4, 但是 5 還沒到就收到 6 的時候,你必須要等 5 收到
這樣才能保證每個更新傳遞的順序是正確的
Transaction
資料庫 - Transaction 與 Isolation | Shawn Hsu 裡面我們知道了各種 Transaction 的細節
重點在 unit of work 對吧,我希望全部的操作都是一起成功或是一起失敗
分散式系統下,你的操作不一定會在同一個資料庫下,那你要怎麼保證 unit of work?
舉例來說,新的使用者註冊服務需要
- user table 新增一筆資料
- permission table 也新增一筆資料
我們學過 partition 以及 replication
所以當上述的 table 不在同一個地方的時候,你要怎麼做 transaction 呢?
Two-phase Commit(2PC)
核心想法是,他依然是 transaction,只是他的 commit 在不同的機器上完成的
為了追蹤每一台機器上的 transaction 的狀況,你需要一個 coordinator(i.e. transaction manager)
他會決定要不要執行這個 transaction,具體來說他會這樣做
他會問每一台參與交易的資料庫,你能不能執行這個 transaction
為什麼會有不能執行的問題? 可能是因為 unique constraint 這種東西或者是其他外力影響(網路斷線,硬碟滿了 … etc.)導致無法 commit
如果有一台資料庫回覆說不能執行,那這個 transaction 就會被取消
注意到,2PC 要求 所有人 都同意才能 commit
反之,如果每一台資料庫都確定可以執行,那 coordinator 會發送 commit 的指令
然後每個人都個別做 commit
所以所謂的 2 phase commit 指的是
- coordinator 確認每個人都可以 commit(prepare phase)
- 由 coordinator 發送 commit 指令(commit phase)
coordinator 扮演著類似
transaction manager的角色
所有節點的 commit 都會由 coordinator 控制,並 assign 一個全域的 transaction id
Issue
2PC 有一個問題,就是當 coordinator 掛掉的時候,整個 transaction 就會陷入一個自我懷疑的狀態
前面提到,2PC 要不要執行交易,是由 coordinator 決定的
也就是說,只有 coordinator 知道要不要做,參與交易的節點是被動的接收指令的
節點接收不到指令,他就不知道要不要 commit,這就是 2PC 的問題
那節點這時候會做什麼?
nothing, 等待 coordinator 的回應 如此而已
所以變成 single point of failure 對吧
對於有一些節點已經 commit 了的情況,這時候 coordinator 掛掉,這些節點就會一直等待,直到 coordinator 回來
恢復了之後,因為 coordinator 有保留之前的決策,所以 2PC 可以保證 eventual consistency
Three-phase Commit(3PC)
3PC 為了解決 coordinator 掛掉的問題,與其讓節點等待,而且不知道要等多長時間
不如讓節點擁有部分選擇的權利
所以 3PC 會多加一個 phase,叫做 prepare-to-commit
順序是 prepare phase -> prepare-to-commit -> commit phase
在真正 commit 之前,他有一個等待的時間,而 3PC 假設這個時間是有限的
我跟你說,我已經準備好 commit 了,但是我要等一下,等 coordinator 給我 commit 的指令
如果 coordinator 一直沒有回應,我就自己 commit(因為 prepare phase 的時候大家都同意可以執行交易)
這個等待的時間有兩個好處
- 維持原本 2PC 交給 coordinator 判斷的權利
- 避免無限等待的情況(非同步處理)
不過分散式系統中,假設擁有有限的等待時間這件事情是錯誤的
有時候單純是因為網路斷線,導致 coordinator 暫時無法回應
這時候 3PC 的缺點就顯現出來了
如果 coordinator 決定 abort
但是因為網路問題,節點 A 沒有收到指令
根據 prepare-to-commit 的結果是 commit,所以它需要等待一段時間
但是因為網路斷線,節點 A 收不到指令
所以就自行 commit
然後你的資料就會出現不一致的問題了
也就是說,前面提到 3PC 假設等待時間是有限的這句是錯誤的
它就只是突然掉個線,你就說它壞了 不對嘛
所以這個假設本質上是要求有一個 完美的故障檢測器
能夠區分暫時網路問題或者是節點真的掛了的狀況
Unstable Network
在分散式系統中,每個節點多為使用網路互相連接起來的
然而網路實際上是不可靠的
網路比你我想像的更不可靠
想想看以下這些問題
- 請求/回應 丟失,封包在路上掉了
- 節點失效,你不知道你的請求有沒有正確的被處理
- 節點暫時停止回應,可能因為目前 request 太多,處理的速度變慢
對於 client 來說,以上這幾種狀況是沒辦法分別的
你唯一能確定的只有,我沒收到回應
那在這種情況下你要怎麼處理?
寫過 web application 的你可能在處理 router 的時候,有寫過類似 timeout 的東西
他的目的也挺簡單的,就是當我超過多久時間沒回應的時候,我就不等了,直接回一個 error
對於分散式系統來說,這也是一個可行的方法
只不過他的 timeout 要怎麼設定?
- 固定 timeout 時間
- 有可能節點只是太忙所以導致回應時間變慢,如果它已經成功寫入,但卻被你回了一個 error,很明顯這是不對的
- 如果我們認為你一直 timeout 是因為節點已經失效了,把你的請求轉移到其他節點,那不是更糟嗎?
- 動態 timeout 時間
- 動態的設定 timeout 時間是不是顯得合理多了?
- 透過實驗或是動態測量網路 round trip 的時間,動態設定,是不是就能夠取得平衡了
Unreliable Clock
有玩過一些單機遊戲的你,可能有發現一個可以偷吃步的方法
有一些遊戲不是會有所謂的每日登入獎勵嗎? 其實你可以透過更改手機或電腦的時間,然後拿到獎勵
這很明顯的是一個開發商的失誤,不過藉此你也可以發現,用時間來判斷一些東西顯然不是這麼的合適
有關時鐘的介紹,可以搭配 Linux Kernel - Clock | Shawn Hsu 一起參考
不同電腦的硬體時鐘可能會有些微的差異(millisecond 之類的)
但即使是在我們看來是這麼微小,每天的誤差可能越來越大,對於精準度極為要求的環境下仍然是不可忽視的
可以使用 NTP(Network Time Protocol) 來同步時間
舉例來說,multi-leader replication 的情況下允許多個節點同時寫入
那它極大可能會出現衝突的情況,上面我們有提到說可以使用 Last Write Wins 或 Version Vector 等等的解法去處理衝突
錯誤的時鐘,有可能會導致錯誤的資料被寫入,而這種錯誤是無法被感知到的
Split Brain
節點的故障有時候是無意的
比如說在 single-leader architecture 下
leader 可能會因為短暫的不可用(GC 導致 stop-the-world, 瞬間流量太大導致處理回應時間變長或是網路異常 … etc.)
而被降級成 follower
但是 old leader 可能沒有意識到它不再是 leader
這個時候就會出現 2 個 leader 的情況
這種情況稱為腦分裂(Split Brain)
有一個解法是這樣子的
透過簡單的 fencing token, 判斷你是否為合法的 leader
其他 follower 會透過這個 token 去尋找合法的 leader
因此,大家都知道誰是真正的 leader
這個 token 本質上就是一個單調遞增的數字,數字大的擁有者就是 leader
問題來了
old leader 恢復上線,並開始運作
這時候 follower 會告訴他說,根據 fencing token 你已經不再是 leader
因為 token 不一樣了,現在的 leader 是別人(token 的擁有者)
透過這樣的機制就可以避免腦分裂的問題
Byzantine Fault
節點的故障有時候是無意的
比如說在太空的環境下
輻射滿天飛,這時候你的硬體是有可能出現不如預期的情況的
這時候你要怎麼修正?
這種狀況通常是依靠特殊能抵抗輻射的硬體或者是準備多台硬體來進行故障恢復
有時候,節點會故意發送錯誤的訊息,意圖摧毀你的系統
這種時候,帶有惡意的故障,被稱為 Byzantine Fault
你說有哪些無聊的人要攻擊你的系統?
以區塊鏈來說,攻擊你的網路,我就可以把別人的錢轉走,這就很有可能了對吧?
著名的 51% Attack 就是典型的 Byzantine General Problem
故事大概是這樣子
不同的將軍想要執行一個作戰計畫
由於將軍們所在地點並不相同
訊息的傳遞都是由傳令兵完成的
如果傳令兵想要叛變,它完全可以發送虛假的消息,欺騙其他人
有關 51% Attack 可以參考 從 0 認識 Blockchain - 區塊鏈基礎 | Shawn Hsu
References
- 資料密集型應用系統設計(ISBN: 978-986-502-835-0)
- 宇航级CPU是如何做到抗辐射的?中美间有多大差距?
- Introducing Netflix’s Key-Value Data Abstraction Layer
- Netflix Tudum Architecture: from CQRS with Kafka to CQRS with RAW Hollow
- Introducing RAW Hollow: An In-Memory, Co-Located, Compressed Object Store with Opt-In Strong Consistency
- NONBLOCKING COMMIT PROTOCOL
Leave a comment