資料庫 - 連線是如何拖垮你的系統的
How Connection Affect your System’s Performance
以 PostgreSQL 來說,他的底層設計是採用 process per user 的 client/server 架構
也就是說,一個 client 的連線會連到一個 server process
不過由於 server 並不預先得知有多少連線會被建立,所以當每一次新連線請求進來的時候,實際上是有一個 master process 負責 spawn 新的 server process 來服務他
所以你可以推論出,當你每一次連接資料庫的時候,都要做 TCP handshake
也就是說每一次你都需要重新開啟網路連接,顯然,這是一個可以改進的地方
這種交握帶來的 tradeoffs 在極端情況下會被放大
進而導致系統的不穩定以及資源的耗盡
有關 TCP 可以參考 重新認識網路 - 從基礎開始 | Shawn Hsu
Introduction to Connection Pooling

ref: 01- Connection Pooling: PostgreSQL Database Administration: Connection Pooling in PostgreSQL 17
所以要怎麼解決這種頻繁握手所帶來的性能消耗
一個直觀的解決方法就是我不把連線斷開,只要他一直存在,我是不是就不會遇到頻繁握手的現象
而這其實就是 connection pool 的基本概念
一開始先把一定數量的 connection 先建立起來
然後把它放在所謂的 pool 當中,當我有需要的時候才把它拿出來用
不需要的時候就把它放回去 pool
注意到在這之中我 並沒有把連線斷開,只是把它放回去池子裡面
Connection Management
說單純的放到一個池子管理很簡單,但實務上要考慮的比較多
基本的你需要指定,比如說 同時最多有多少連線正在使用
或者是 池子內最多有多少連線可以存在
其中最重要的是,連線的有效期限
有效期限是什麼意思? 我們的目標不是盡量減少連線的建立那些嗎
設定 expire 不就違反了我們的初衷
如果連線長時間沒有被使用,那繼續開著是不是也沒啥用,那不如就把它關掉(因為開著也是會佔一些資源)
等到 client 真的需要的時候再重新建立
話雖如此,他還是會有基本的連線數量維持著
有時候連線存在太久其實會導致錯誤(i.e. Broken pipe)
所以檢查去清除錯誤連線也是必要的
通常來說,這個檢查是被動式的較多(也有背景程式),當 connection pool 把連線交給你之前他會做一系列的檢查
確保你不會拿到過期或甚至毀損的連線
How About Unlimited Connection
無上限的連線池實際上是將 等待連線的排隊壓力 從應用程式端轉嫁到了資料庫端
應用程式排隊只需消耗微量記憶體,而資料庫端排隊則會引發 context switch 與 I/O 競爭
顯然這樣對資料庫是很不友好的
等於說,reuse 以及 cache 的功能在這個狀況下完全失去作用
你應該要設定合理的連線上限,而不是無止境的讓他爆炸
PostgreSQL Connection Benchmark
那就來實際的測量看看到底差多少
Prerequisites
1
2
3
4
5
6
7
8
9
10
$ uname -a
Linux station 6.8.0-107-generic #107~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Wed Mar 18 23:40:43 UTC x86_64 x86_64 x86_64 GNU/Linux
$ docker -v
Docker version 29.3.0, build 6927d80
$ go version
go version go1.25.5 linux/amd64
starting PostgreSQL 15.4 (Debian 15.4-1.pgdg120+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit
Sequential Experiment
為了實驗的嚴謹性,只採用 database/sql 的內建套件
並使用 Golang 搭配 PostgreSQL 進行測量
測量的方法是透過設定 db.SetMaxIdleConns(0) 的方式,確保不會有任何 Idle 的 connection
換句話說,就是可以確保每一次你使用連線的時候,他都必須去跟 database 拿
If n <= 0, no idle connections are retained.
預設情況下測量 10000 次取平均值
並且因為我們只在乎連線的時間,所以 SQL 方面就只是簡單的 SELECT 1
雖然測量會包含 query 時間,不過因為變量是固定的,所以最終測量出來的結果就只有 connection pool 的差別而已
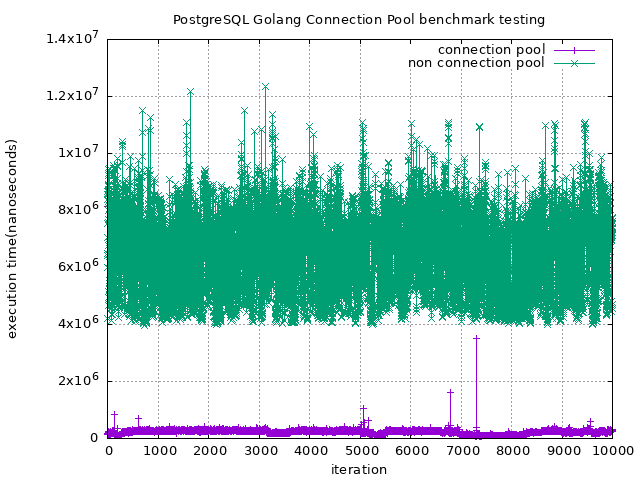
你可以看到,無論何時,使用 connection pool 的情況下
平均會差到 $4 \times 10^6$ nanoseconds 這麼多
所以實驗可得,有沒有使用 connection pool 對於效能仍然具有一定的影響
Concurrent Experiment
那同時我也好奇說,connection pool 裡面的連線如果都被拿光,那剩下的 request 會如何反應
其實只要調整 db.SetMaxOpenConns 就好,因為他可以限制目前同時最大連接數
如果設定 max open conn 為 3,然後同時開 10 個 request 下去會如何
注意到在 application layer 不要自己用 channel 去做 blocking
因為你想看的其實是 connection pool 會不會 block 你

我總共跑了 10 次的測試,每次測試都是 10 個 request 搭配 3 個 max open conn
你可以很明顯的觀察到,他的確是三個一組在執行,並且之後的 request 進來他的等待時間會跟著上升
表示說確實同一時間他可以最多服務 max open conn 這麼多的連線
這邊方便觀察,圖表是有經過排序的,因為每一組都是透過 goroutine 去啟動的
沒排過序的長這樣
你可以看到先啟動的 goroutine 不一定是先跑的

Server Side Pooling
我們知道 database/sql 內部會自己幫你做 connection pool(可以參考 PostgreSQL Connection Benchmark)
可是這並不足以在現今的架構中容易存活
因為這種設計是只針對 application level 做的設定
也就是說當你 scale out 的時候,每個 go program 都有自己的 connection pool
那有可能連線總量撞到資料庫等級的設定,那就沒什麼幫助了對吧
所以現在 Server Side Pooling 的做法備受關注
比方說 PgBouncer 這類的解決方案
把 connection pool 獨立拉出來,這樣就不會受限於 application level
連線的時候,你是跟 PgBouncer 溝通而不是 PostgreSQL 本身

ref: 你當然需要 PgBouncer 啊
References
- 從連線到效能:SQL 套件 Connection Pool 的底層設計與優化技巧
- database/sql: connection pool was originally FIFO, is now random, but should be LIFO
- 你當然需要 PgBouncer 啊
- 01- Connection Pooling: PostgreSQL Database Administration: Connection Pooling in PostgreSQL 17
- 51.2. How Connections are Established
- Processes in PostgreSQL - Internal of PostgreSQL
Leave a comment