多開 Goroutine 的效能瓶頸以及 Garbage Collection 對其的影響
Preface
Goroutine 作為 Golang 的一大特色
其輕量且快速的特性,使得其的開銷相比 process 以及 thread 要來的低上許多
因此人們往往會將 Goroutine 用在非同步的操作上,比如說 I/O 或者是 CPU-bound 的操作
用以達到併發的效果
有關 Goroutine 的介紹可以參考 Goroutine 與 Golang Runtime Scheduler | Shawn Hsu
Goroutine 本身屬於 coroutine,縱使他的開銷相對較低,也還是會有一定的成本
比如說 Golang Runtime Scheduler 必須要管理這些 Goroutine 進行任務調度
頻繁的 context switch 會導致 scheduler 本身都在處理調度任務,反而實際的任務根本沒在執行
這些種種的問題都是我們在開發時需要注意的地方
而本篇文章將會詳細的探討 Goroutine 本身的開銷以及 Garbage Collection 是如何處理這些 Goroutine 的
Stack vs. Heap Allocation
有哪些東西是不會被 GC 處理的?
non-pointer 的 value 是不需要被 GC 處理的(slice 那些除外)
因為在 compile time 的時候就可以決定他的生命週期了
這種資料位於 stack 上,普遍被稱為 stack allocation
針對那些動態的記憶體存取,比方說根據使用者的輸入決定記憶體大小
或者是指標類型的,因為你不太能確定這塊記憶體會被怎麼用以及哪時候可以安全的被回收
這種動態的記憶體存取就是 GC 需要主動介入的
Introduction to Garbage Collection
以前在學 C 語言的時候,或多或少可能都聽過 malloc 完要記得 free 這句話
這是因為在 C 語言中,記憶體的管理是由開發者自己來負責的
如果你忘記 free 掉你 malloc 的記憶體,就會造成 memory leak
阿 人類就很懶惰嘛,所以就想說能不能有一個機制來幫我們管理記憶體
Garbage Collection 就是這樣一個機制,它會自動幫你管理記憶體
當你沒有要使用記憶體的時候,GC 會自動幫你回收這些記憶體(所以你可以用完就丟著,有人會幫你收拾)
local variable 不需要讓 GC 處理,因為 compile time 就可以決定他的生命週期了
需要 GC 通常是你不知道哪時候不會用到,可以被回收,比如說 slice
GC 有很多種實作,比如 Reference Counting 以及 Mark and Sweep
GC Mechanism
Reference Counting
怎麼定義這塊記憶體可以被回收? 最簡單的想法就是看他有沒有正在被使用
假設這塊記憶體正在被 2 個人使用,那想當然不要回收它是比較正確的
這種作法被稱為 reference counting
當你把每個變數的 reference count 都記錄下來
當 reference count 為 0 的時候,就可以把這塊記憶體回收了
Mark and Sweep
Mark and Sweep 是另一種 GC 的實作方式
他是 Tracing GC 的一種,這種方式會建立一個 依賴關係圖(稱為 object graph)
這個關係圖會紀錄每一個 object 彼此使用的關係,所以你可以很輕易的觀察哪些資源正在被使用
之後就可以透過這張關係圖去區分說哪些資源是可以被回收的
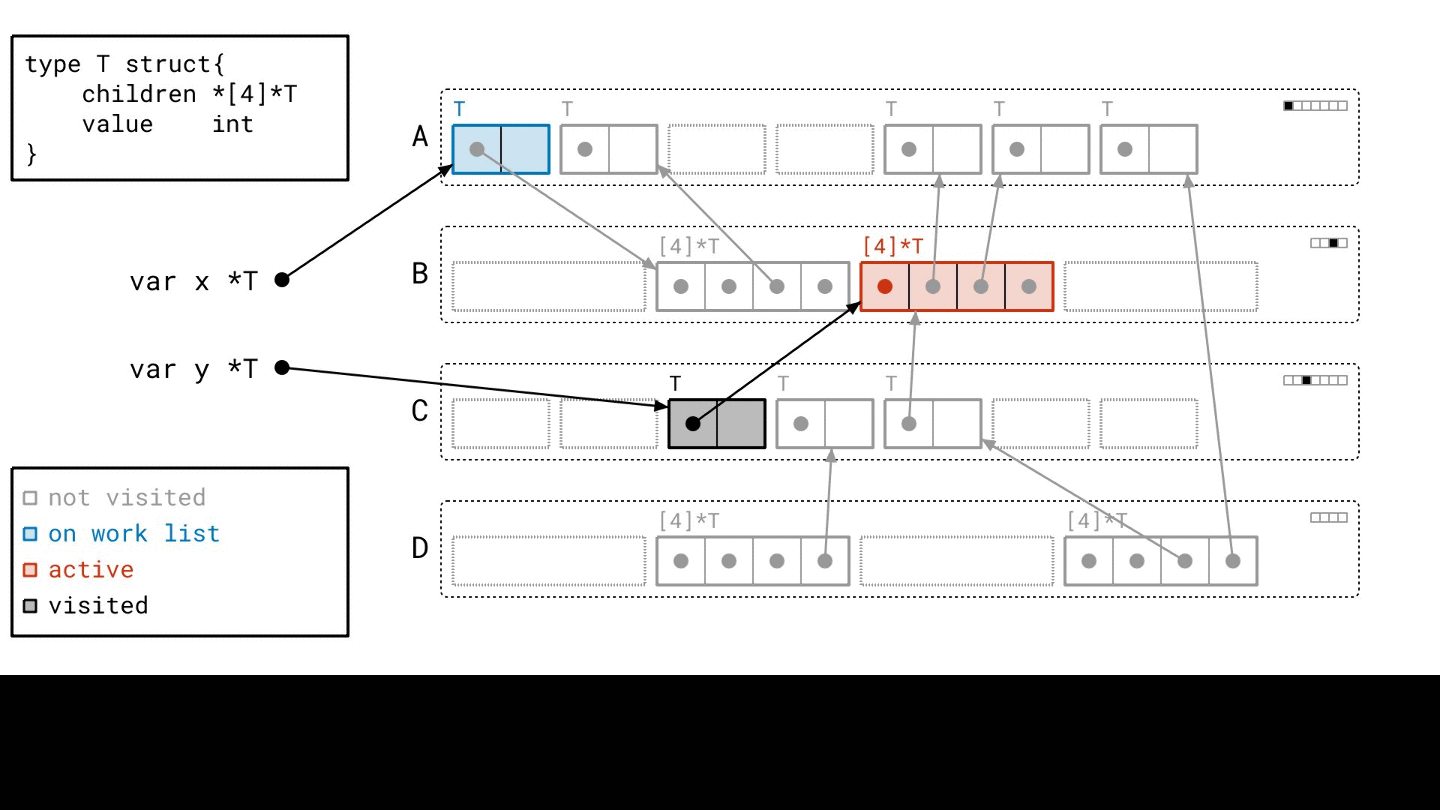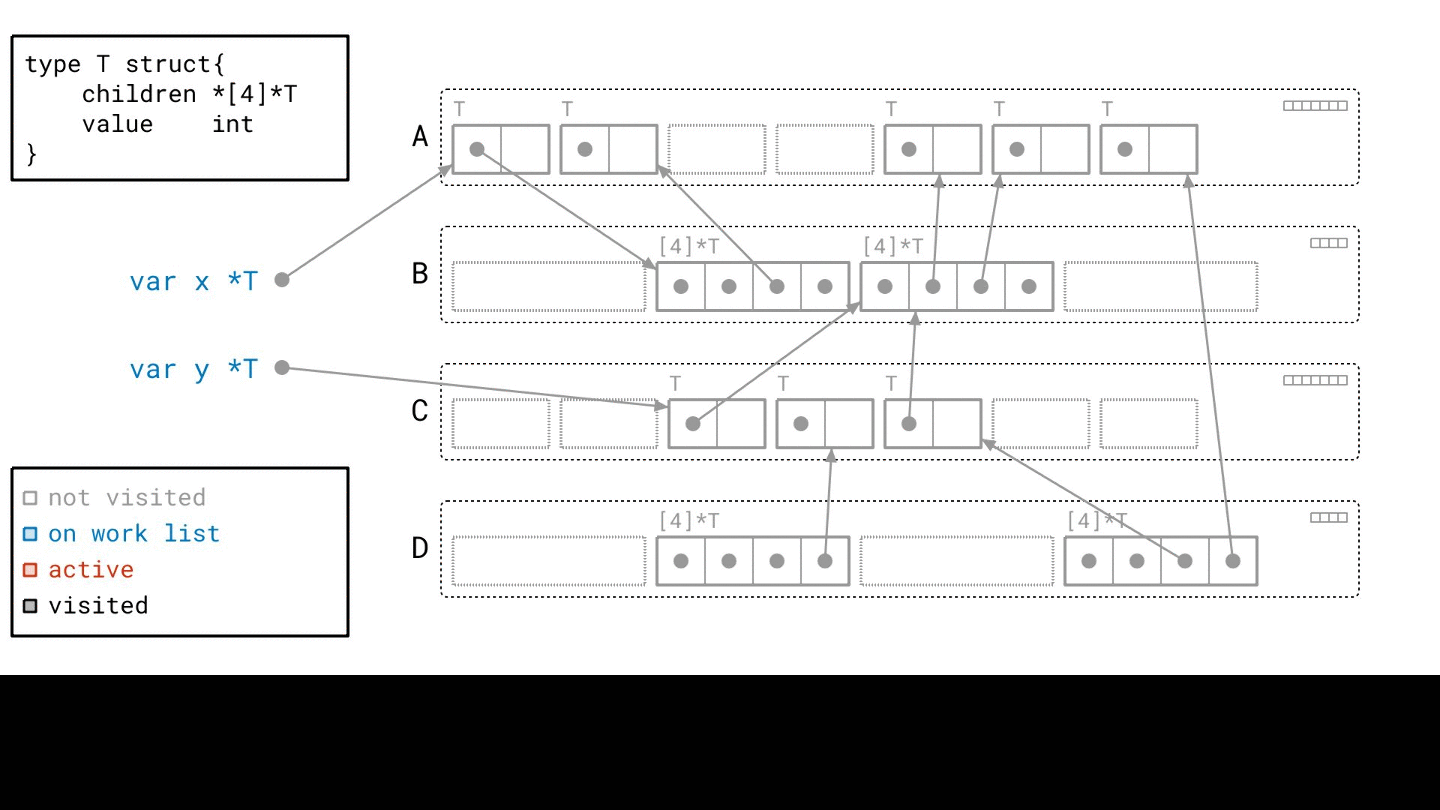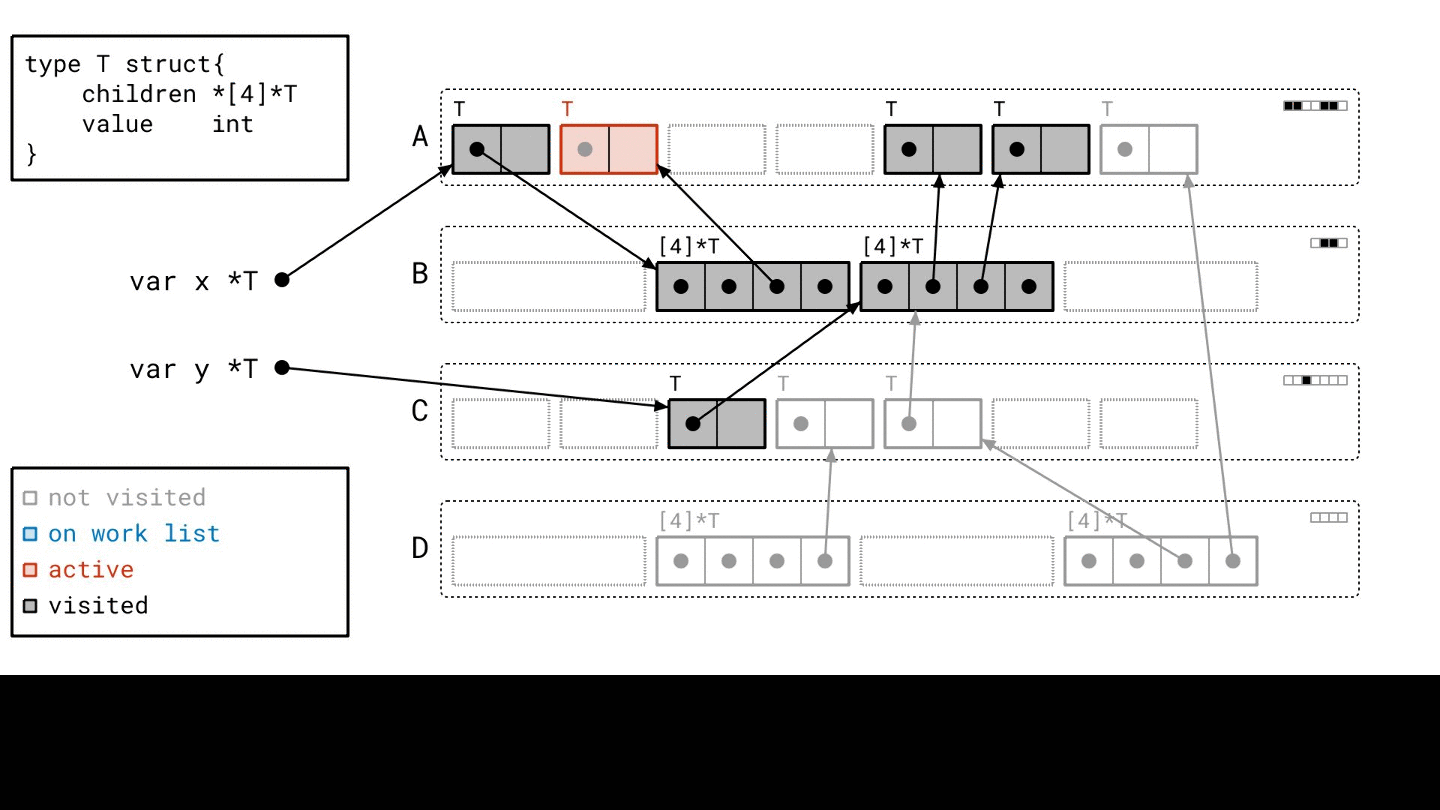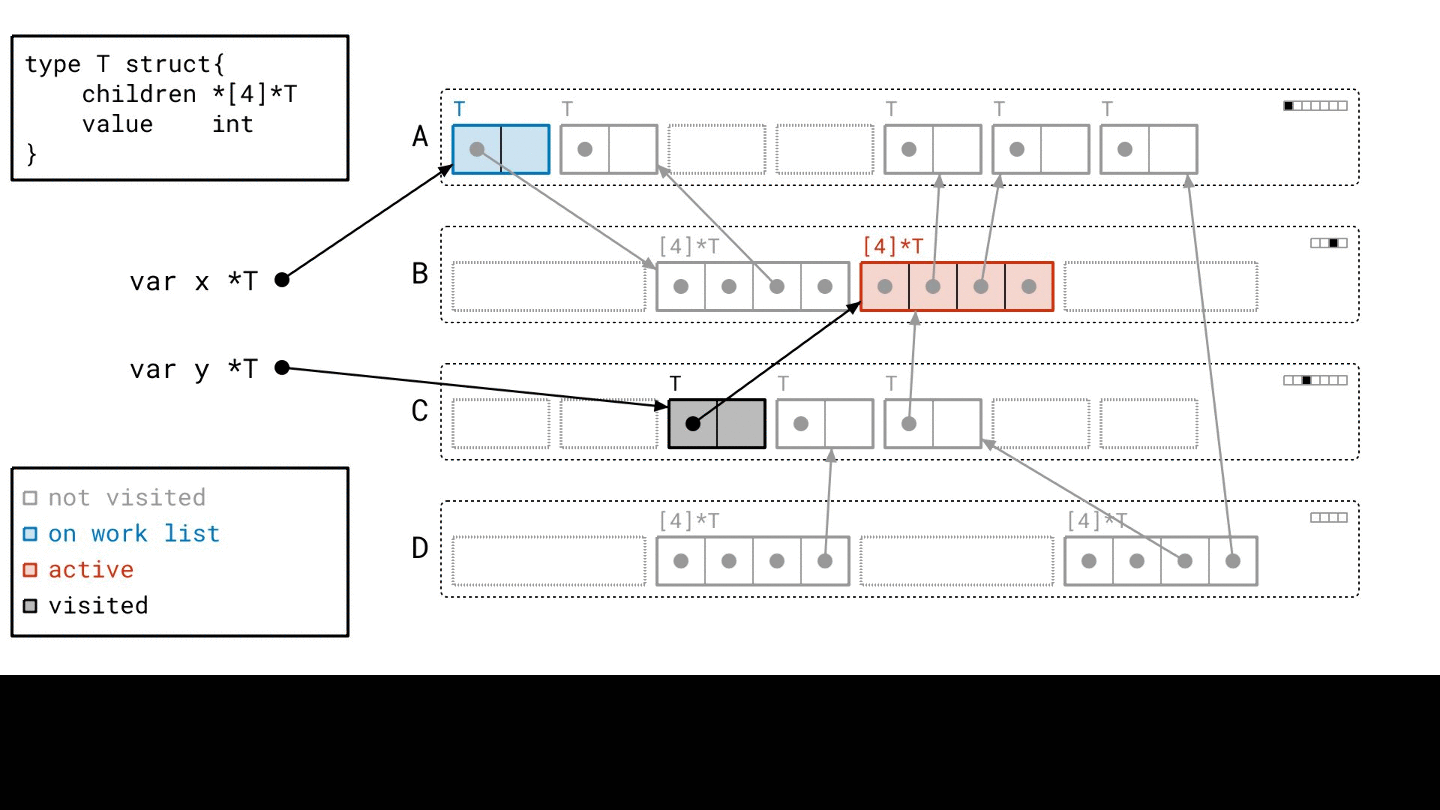
你需要兩個步驟執行它
- 建立 object graph(i.e.
scanning) - 掃描 object graph 並回收不需要的記憶體(i.e.
mark and sweep)
具體一點來說,GC 會走訪整個 object graph(從 root 開始)
-
mark- 每一個走到的 object 它都會標記一下,表示這個 object 是活著的(i.e.
live)
- 每一個走到的 object 它都會標記一下,表示這個 object 是活著的(i.e.
-
sweep- 全部都標完之後,那些沒有被標記到的 object 就可以被回收了
這個就是 mark and sweep 的概念
Cyclic Reference
你會想,建立 object graph 不就是 Reference Counting?
不一樣! 因為 Reference Counting 沒辦法區分出 循環引用的問題
cycle import 的情況下,reference count 會永遠不會歸零,所以這塊記憶體永遠不會被回收
但是 Mark and Sweep 不會
因為 object graph 其實是有 root 節點的,這些 root 節點可以是 local/global variables
從 root 節點往下找所有 object 使用情況,如果遇到 循環引用 但是它沒辦法從 root 節點走到,那它還是會被回收
所以 Mark and Sweep 可以正確的回收這些循環引用的記憶體
Moving vs Non-moving GC
各位不曉得還記不記得所謂的 Fragmentation 問題
你動態分配的記憶體 free 掉之後,就會這邊一塊那邊一塊的
等到你真的需要一塊很大的連續記憶體的時候,你就沒辦法操作
這種情況是所謂的 External Fragmentation
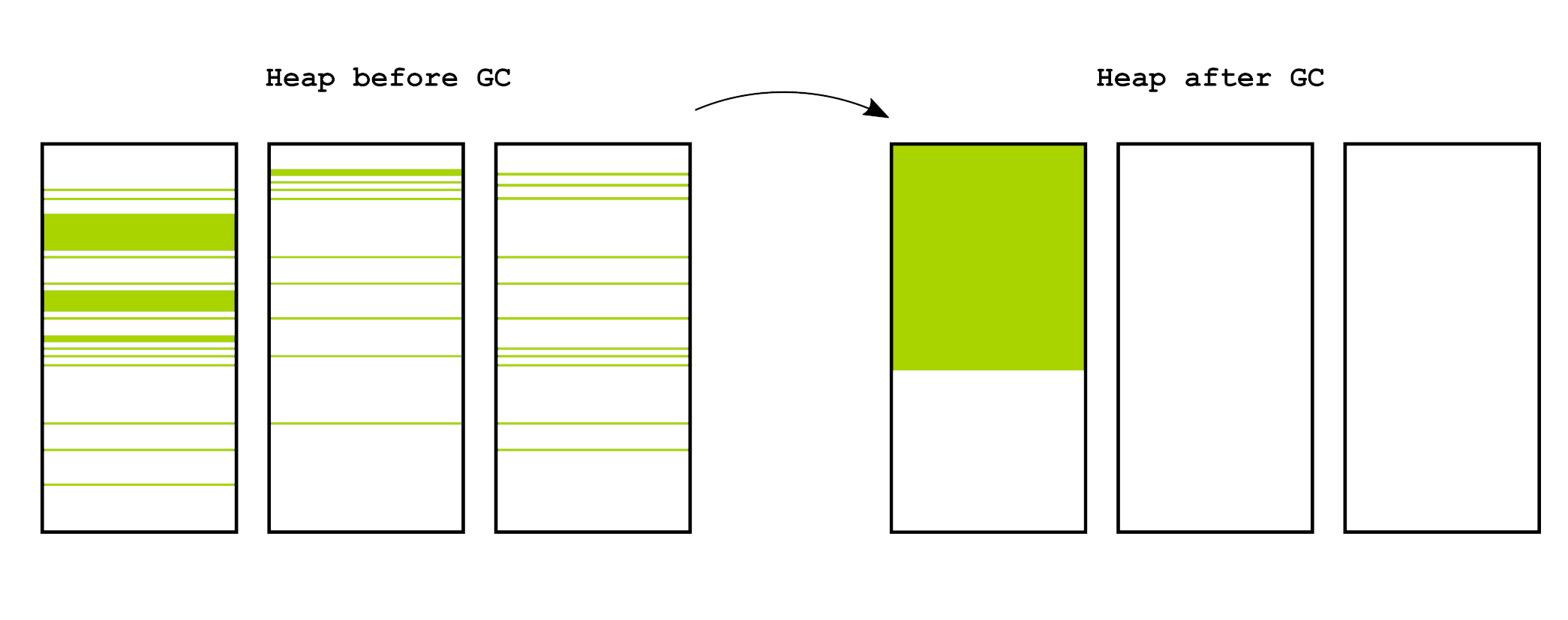
GC 同樣也會面臨到相同的挑戰,既然記憶體是分散的
你是不是能手動把它整理在一起(就是每一塊記憶體都是緊緊貼著彼此的),這樣碎裂化的問題就可以得到緩解?
這種方式稱為 Moving GC
具體來說怎麼做呢?
GC 會幫記憶體搬家,但是呢 所有使用到相同記憶體的地方都要更新(很合理嘛不然東西會錯掉)
為了確保你不會存取到錯誤的記憶體,在這個階段你的程式會被暫停
舊的記憶體位置放所謂的 forwarding pointer,這個 pointer 指向新的記憶體位置
GC 會走訪整個 object graph,當碰到 forwarding pointer 的時候它就會更新成新的記憶體位置
到最後所有相對應的 reference 都會被更新
1
2
object -> old memory location
object -> forwarding pointer -> new memory location
Garbage Collection Trade-offs
在上計算機組織的時候,有一個概念是 要讓常跑的東西跑得快,這樣整體效能就會有很大的提昇
對於 Garbage Collection 來說,也是一樣的道理
GC 需要不間斷的運行,才能確保最高的記憶體利用效率
但是一直執行垃圾回收,對你本身的 application 來說也是會有一定的影響的
比如說你的程式會被暫停,這樣的話你的程式就會變得很慢
垃圾回收機制本身會有哪些開銷呢?
| type | description |
|---|---|
| CPU time | 能夠影響 CPU time 的會是 object graph 的大小因為如果圖很大,走訪的時間就會比較久 |
| Memory |
object graph 會直接影響到記憶體的使用量並且加上其他 metadata,這些都會佔用記憶體 |
真實世界中,你的記憶體不大可能是一直平穩的(i.e. steady-state),比較多時候會是一下高一下低的狀況
比方說 web application, 可能遇到做活動流量突然爆增,這時候 GC 的開銷就會變大
而且你還要考慮這些記憶體,有可能會經過很多個 GC cycle, 也就是它執行很久(釋放的少,使用的多)
我們可以藉由調整 GC 執行間隔換取不同的效能
比如說你想要節省 CPU 你就可以把 GC 的執行間隔拉長,但是這樣的話記憶體就會被佔用很多(因為沒清理)
同樣的,如果你想要節省記憶體,你就可以把 GC 的執行間隔拉短,但是這樣的話 CPU 就會被佔用很多(因為一直跑)
舉例來說
- 假設一個 golang app 處於
steady state,記憶體使用量是10MiB/s(意思就是每秒固定多 alloc 10MiB 的記憶體) - 假設當前 live heap 的大小是
10MiB - GC 需要花費 1 cpu-second 掃描
100MiB的記憶體
如果
- GC 執行 cycle 是 1 cpu-second,那麼表示
- 在 1-cpu second 內,有 額外的 10MiB 記憶體被索取,目前的 live heap 大小是原本的 10MiB 加上 10MiB,總共
20MiB - GC 需要花費 0.1 cpu-second 來掃描 當前的 live heap(也就是
10MiB) - 所以 GC 佔用 CPU 的使用率是
10%
- 在 1-cpu second 內,有 額外的 10MiB 記憶體被索取,目前的 live heap 大小是原本的 10MiB 加上 10MiB,總共
- GC 執行 cycle 是 2 cpu-second,那麼表示
- 在 2-cpu second 內,有 額外的 20MiB 記憶體被索取,目前的 live heap 大小是原本的 10MiB 加上 20MiB,總共
30MiB - GC 需要花費 仍然是 0.1 cpu-second 來掃描 當前的 live heap(也就是
10MiB) - 所以 GC 佔用 CPU 的使用率是
5%
- 在 2-cpu second 內,有 額外的 20MiB 記憶體被索取,目前的 live heap 大小是原本的 10MiB 加上 20MiB,總共
為什麼 GC 只掃描 live heap 而不是整個 heap
你不需要掃描完整的 heap,如果套用 Mark and Sweep
從當前 live heap 如果走不到,那就代表它可以被回收
所以實際上的開銷會是 1.) 當前 live heap 的大小以及 2.) 能夠從 live heap 被走到的少量記憶體(額外的記憶體)
當你調整 GC cycle 的速度調慢 50% 的時候,雖然 GC 的 CPU 使用率 降低 50%,但是記憶體使用量 增加 50%
GOGC
你可以透過調整 GOGC 的參數
GOGC 的數值是 CPU 與 memory 的 trade-off
當數值越大,Target Heap 的容量越大,GC 的間隔會被拉長,進而導致 CPU overhead 降低,反之亦然
設計上 Target Heap memory 會影響 GC 的間隔,它就是這樣設計的
GOMEMLIMIT
不過無限上調 GOGC 的數值是不合理的,因為記憶體數量終其有上限
所以可以設定 memory limit(i.e. GOMEMLIMIT)
這個限制主要是針對 Heap memory 的限制
不過如果你設定了 memory limit 又把 GC 關閉,就會造成 Thrashing 的狀況
你把 GC 關了意味著記憶體不會回收,同時設定記憶體上限,最終記憶體就會被用光
進而導致你的程式逐漸失去回應(i.e. stall)
為了避免這種狀況發生,Golang Runtime 其實將 memory limit 視為是 非硬性規定
因為如果你兩個都設定了,最終一定會導致 Thrashing 的狀況發生
那不如讓你 bypass 掉這個限制,讓你的程式能夠繼續跑比較重要 是吧?
也就是說 application 可以拿到 CPU time 來跑,換句話說,GC 分到的 CPU time 就會變少
等於 GC 的 cycle 會被拉長,可以理解吧
cycle 拉長,一個 cpu-second 內原本能跑 0.3 cpu-second 的 GC,現在只有拿到 0.1 cpu-second 的 GC
原本等待時間是 0.7 cpu-second 變成 0.9 cpu-second
GC 在一個 cycle 內能使用的 CPU time 通常會有一個上限,比如說最多只能佔 50% 的 CPU time
這樣的好處在於說,你的 application 最差只會慢 一倍
GC 關掉,100% CPU time 都是 application 拿,假設花 10 秒
GC 開啟,50% CPU time 是 GC 拿,50% CPU time 是 application 拿,因為每個 cycle application 執行時間少了一半,所以總共花 20 秒
因此是10秒變20秒,所以是一倍
Evolution of Golang Garbage Collector
Stop-the-World Mark and Sweep
Golang 早期的實作是 Mark and Sweep 並且屬於 Non-moving GC
根據不同的 GC 實作,有的會需要 Stop-the-World(i.e. STW) 的機制,也就是說你的程式會被暫停,直到 GC 完成
這種作法無疑是犧牲了應用程式的效能,Golang 在這方面,選擇 GC 與 application 同步執行(i.e. not fully Stop-the-World GC)
即使是 Stop-the-World 的作法,Mark and Sweep 還是要走過完整的 Live Heap
也就是說 STW 的情況下,GC 暫停的時間與 Live Heap 的大小成正比
又因為 STW 會導致應用程式暫停,所以 latency 會被拉高
latency 維持比較低通常是比較好的狀況,代表使用者可以有比較好的體驗(按下按鈕到看到結果的時間是相對短暫的)
既然 STW 的作法會導致較高的延遲,自然而然就變成 not fully Stop-the-World GC 的實作
low latency != low throughput
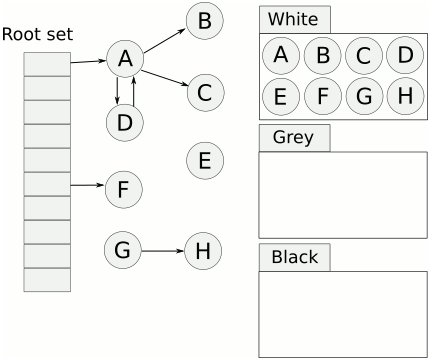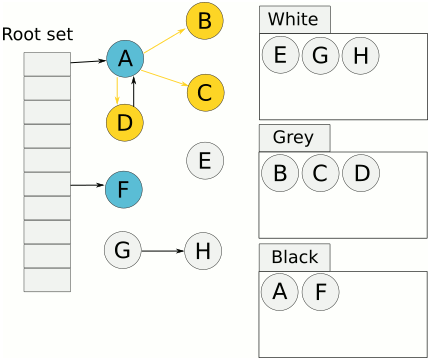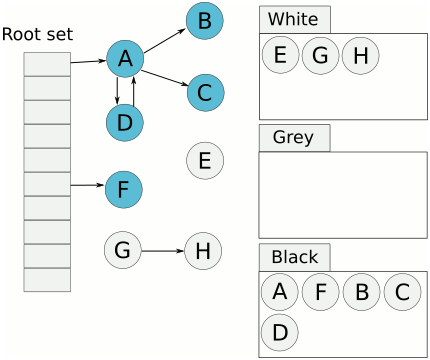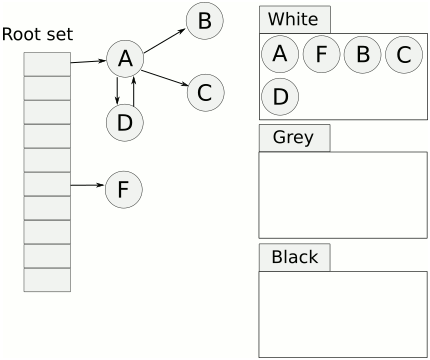
Tricolor Mark and Sweep
相比於 Mark and Sweep,Tricolor Mark and Sweep 在實作上引入了額外的一種狀態(處理中 的狀態)
使 GC 可以針對不同狀態的 object 進行不同的處理
這些狀態我們會使用三種顏色表示
| color | description |
|---|---|
white |
沒辦法被拜訪到的 object,之後可以被回收 |
gray |
可以拜訪到的 object,但是需要進一步掃描 |
black |
確定正在使用中的 object |
當 GC 開始的時候,所有的 object 都會被標記為 white
從 GC root 開始先把走得到的標記成 gray
再把 gray 標記為 black 直到所有 處理中(gray) 的 object 都消失
這時候只剩下 white 跟 black 的 object
因為我們確定說 black 的 object 是正在使用中的 object,所以就繼續放著
至於 white 的 object 就是可以被回收的 object
至此,GC 就完成了
但是光有 Tricolor 的機制其實還不足
既然 Golang 選擇 not fully Stop-the-World GC,其中一個挑戰就是如何確保資料的正確性
不同於 Mark and Sweep 這種 STW GC
同時執行 GC 與 application,因為 app 會去動記憶體嘛,那是不是有可能之前標記過得資料被移動,導致 GC 標記錯誤
然後執行就會有問題
Write Barrier
即使是 Tricolor Mark and Sweep,GC 本身也需要額外透過 Write Barrier 的幫忙來解決記憶體移動,然後標記的問題
注意到 Race 本身還是存在的,只是說 Write Barrier 可以確保這個 Race 的結果會被 GC 所得知,進而避免錯誤的處理
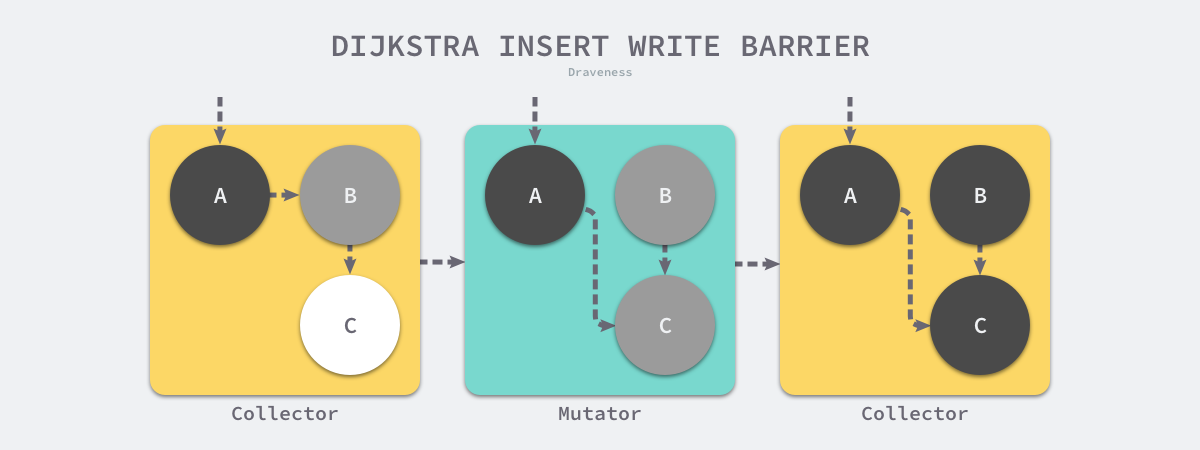
舉例來說,假設 A 已經被標記為 黑色 (Black)(代表 GC 已掃描完 A),而 B 是 灰色 (Gray)
原本的連結是 B -> C
但是呢,app 突然將連結改成 A -> C 並切斷了 B -> C
在沒有 Write Barrier 的情況下:
- 下一個掃描步驟會把 B 標記為黑色,但因為 B -> C 已斷開,GC 沒機會把 C 染灰
- 而 A 已經是黑色,GC 不會回頭再掃描 A,所以也不會發現 A -> C
- 最後,C 仍維持 白色 (White),導致這個還在被使用的物件被當成垃圾回收掉
所以 Write Barrier 就是用來解決此類問題的
Dijkstra barrier
至於說他是怎麼做的呢?
首先,Tricolor 的 GC 需要嚴格遵守以下的 invariant
No
blackobject may contain a pointer to awhiteobject.
啥意思? 因為 white object 會被 GC 掉,但如果被 reference 到,它應該要是 gray 的
再來的問題是,我要檢查誰? 只有指標是需要的,一般變數因為生命週期是可以預期的,所以 GC 可以不處理
當任何 pointer update(i.e. read、write 或是 read and write) 發生的時候都需要做再一次的檢查
為什麼是當 pointer update? 因為 GC 是透過 pointer 來拜訪 object 的
它指到誰 指到哪 很重要
怎麼做就有趣了
Golang 原本只有單純的 Dijkstra barrier
實作上來說也挺簡單的
1
2
3
writePointer(slot, ptr):
shade(ptr)
*slot = ptr
shade() 必須先將 ptr 標記為 gray
因為如果他是白色的,就會違反 invariant
把它變成 gray 的另一個目的是讓 GC 不要把 ptr 當成是 white object 回收掉
不過他也有缺點
Write Barrier 中提到的問題,Dijkstra barrier 本身有兩種方式可以解決
- 你需要一個
Stack Memory Barrier - 你必須確保 stack 上的資料是
permagray(永久灰)
Golang 選擇後者(因為 Stack Memory Barrier 的成本太高),但是要怎麼保證 stack 上的資料是 permagray 呢?
你需要一直去檢查 goroutine 的 stack 內的東西是不是合法的(i.e. 符合 invariant)
舉例來說,Heap 內的指標可能會指向 Stack 裡的 White Object
當碰到這種狀況,你必須要確保 Stack 內的 White Object 不會被回收掉
所以重新掃描是必要的(i.e. Stack Rescan)
但這個掃描是很頻繁且耗時的
GC cycle 開始之前要掃一次,結束之前也要再掃一次
每一次的掃描其實都需要 Stop-the-World,不然 stack 內的資料有可能會被改動
Re-scanning the stacks can take 10’s to 100’s of milliseconds in an application with a large number of active goroutines.
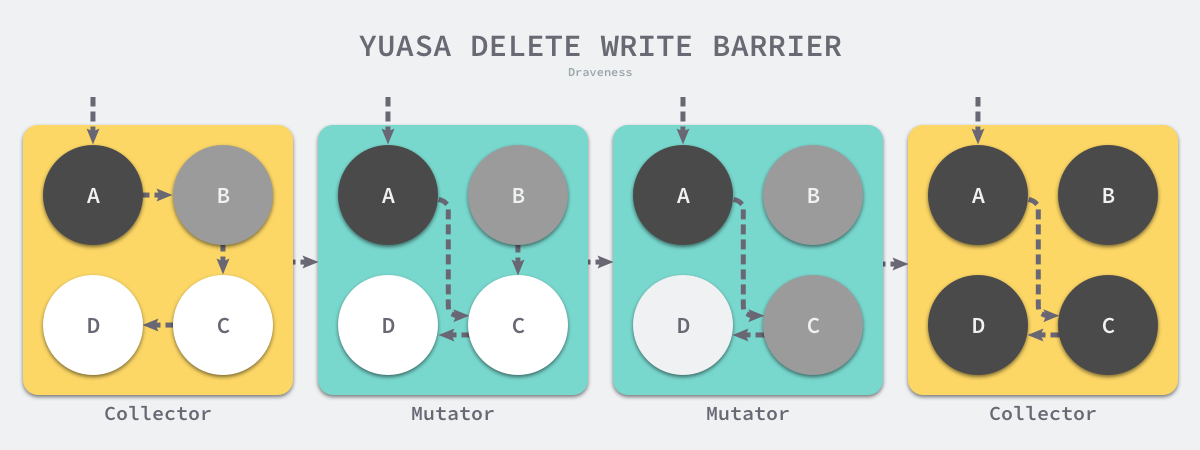
Yuasa-style Deletion Write Barrier
Yuasa-style deletion write barrier 與 Dijkstra barrier 的差別在於,Yuasa-style 是標記 被刪除的 object 為 gray
而 Dijkstra barrier 是標記 被更新的 pointer 為 gray
所以 Yuasa-style 才稱為 Deletion Write Barrier
ptr 不需要 shade 嗎? 因為它其實是被 “chain” 起來的,所以 GC 會找到它
實作上就會是
1
2
3
writePointer(slot, ptr):
shade(*slot)
*slot = ptr
範例圖中要記得,shade() 的對象是 B,因為他才是被拔掉的 object
不過它有比 Dijkstra barrier 還要好嗎?
Yuasa 在 pointer update 之前就會先 shade 舊值,因此不論它被移動到哪裡去,GC 都會找到它
也因為這個特性,Yuasa 的作法不需要 Stack Rescan
Hybrid write barrier
而為了要解決 Dijkstra barrier Stack Rescan 的缺點
新版 Golang GC 的架構採用 hybrid write barrier 來解決這個問題(結合了 Dijkstra barrier 與 Yuasa-style deletion write barrier)
最終 write barrier 的實作會長這樣
1
2
3
4
5
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr
結合了兩種作法的優點
- Dijkstra barrier: 允許 concurrent scan
- Yuasa-style deletion write barrier: 不需要 Stack Rescan
雖然 Dijkstra 與 Yuasa 都允許 concurrent scan,但是 Dijkstra 的 concurrent 程度更高
但是新的 hybrid write barrier 實際上無法滿足 Tricolor 的 invariant
相反的是,提供了一個 稍微弱的 invariant
No
blackobject may contain a pointer to awhiteobject.
Any white object pointed to by a black object is reachable from a grey object via a chain of white pointers (it is grey-protected).
自始至終 GC 的挑戰都是要能夠避免 “mutator” 隱藏 object 的問題
這個稍微弱的 invariant 允許隱藏得很深的 white object 能夠被 GC 所感知,那基本上要能夠走訪就代表它應該是在同一個 “chain” 上的
-
shade(*slot)- 借鑒 Yuasa-style deletion write barrier 的作法,使其不需要進行 Stack Rescan。這個操作可以在 “從 Heap 搬遷到內部 Stack 的過程中” 防止 mutator 試圖隱藏 object
-
shade(ptr)- 借鑒 Dijkstra barrier 的作法。這個操作可以在 “從內部 Stack 搬遷到 Heap 的過程中” 防止 mutator 試圖隱藏 object,不過如果 stack 已經掃完然後變
black,那就不需要了(原本要把 ptr 標記為gray做後續處理,但因為 ptr 本身在的 stack 已經掃完了,所以不需要)
- 借鑒 Dijkstra barrier 的作法。這個操作可以在 “從內部 Stack 搬遷到 Heap 的過程中” 防止 mutator 試圖隱藏 object,不過如果 stack 已經掃完然後變
Green Tea Garbage Collector
針對 Mark and Sweep 的算法來說,幾乎所有的成本都是在 mark 的過程,sweep 一直以來都沒什麼大問題
具體的差別大概是 90% mark 以及 10% sweep
而在 mark 階段中,大約會花費 35% 的時間是在等待 heap memory 的存取,這顯然是一個可以優化的空間
而造成這個問題的原因是,多數資料是分散在記憶體中的
GC 在執行的時候如果東西不在旁邊(i.e. cache),就需要跑到 main memory 去拿
而這會浪費很多時間
與其這樣做,不如盡量讓所有資料存取可以在附近就拿到
這樣我們可以縮短 memory 的存取時間,進而提昇 GC 的效率
新的 GC 算法旨在解決上述效能問題
不過它本質上也還是 Mark and Sweep,其核心的概念是
Work with pages, not objects
雖然說是處理 page, 但實際上你還是要處理 object,在某種程度上
所以新的架構會需要 metadata 來做這件事,這個 metadata 有兩個部分
-
seen: 代表這個 object 被看過 -
scanned: 代表這個 object 被掃描過
奇怪了? 為什麼要區分 seen 跟 scanned 呢?
你看過不就等於掃描過了嗎
其實這正是 Green Tea 的精髓所在
早期,每一個 object 只會被加入 work list 一次,但是 page 的方法下,每一個 page 都會被加入 “很多次”
而且不同的地方在於,如果他有 reference 到其他 object,他只會跑過去 標記 seen 而已,他並不會直接跑去掃描他
等到我掃描完一個 work list 之後,我再從 metadata 中找出那些被 seen 過的 object,並且把他們加入到 work list 中
這也是 Green Tea 效率高的關鍵
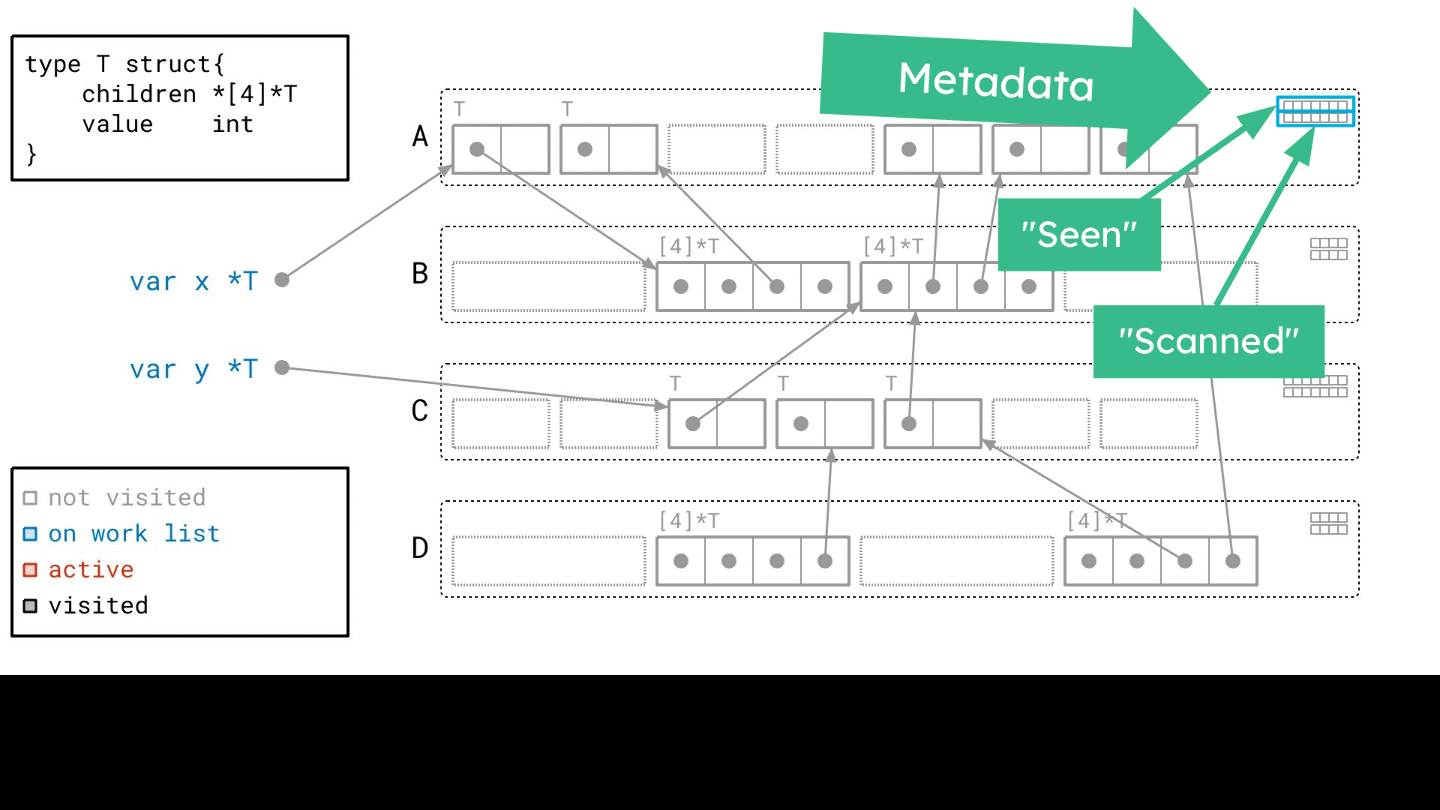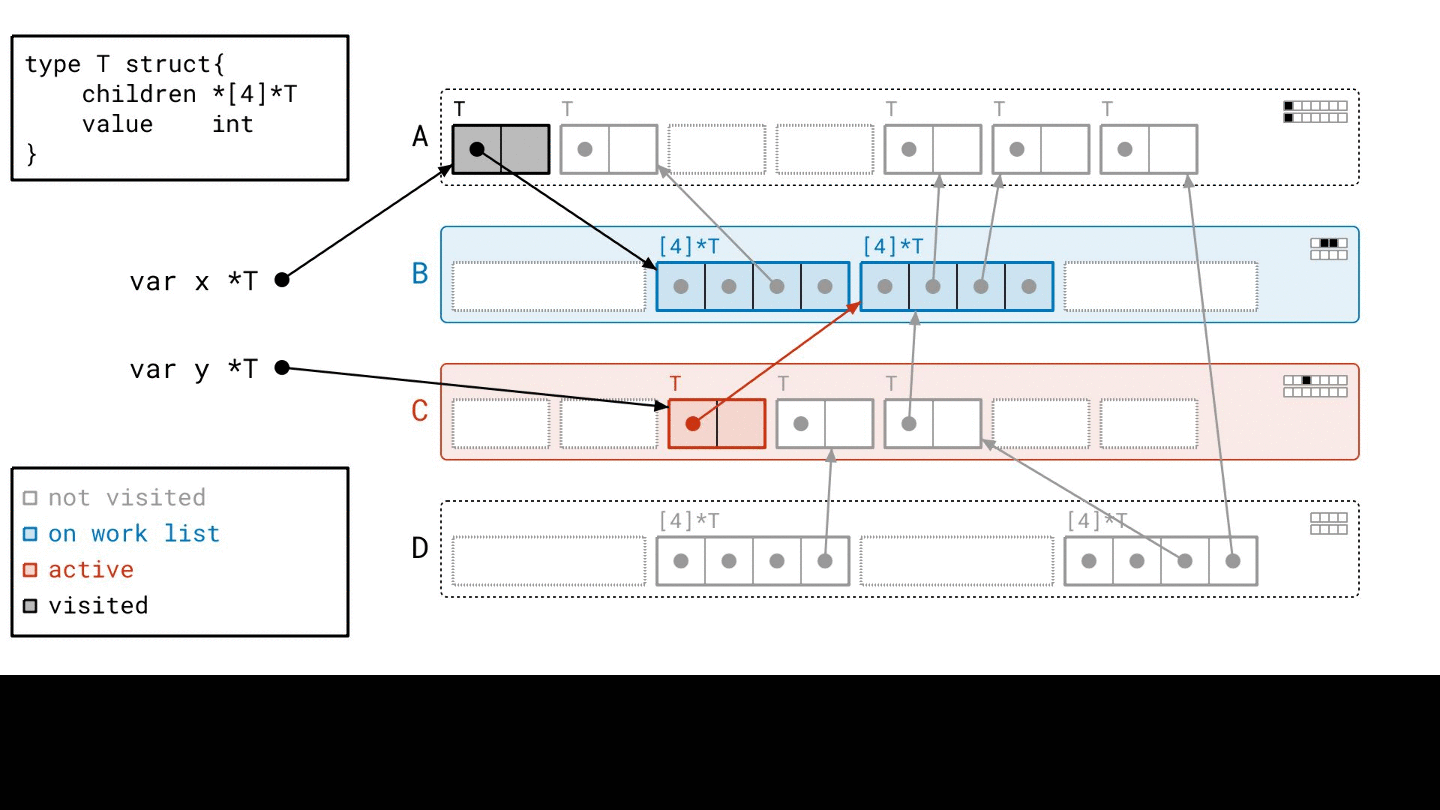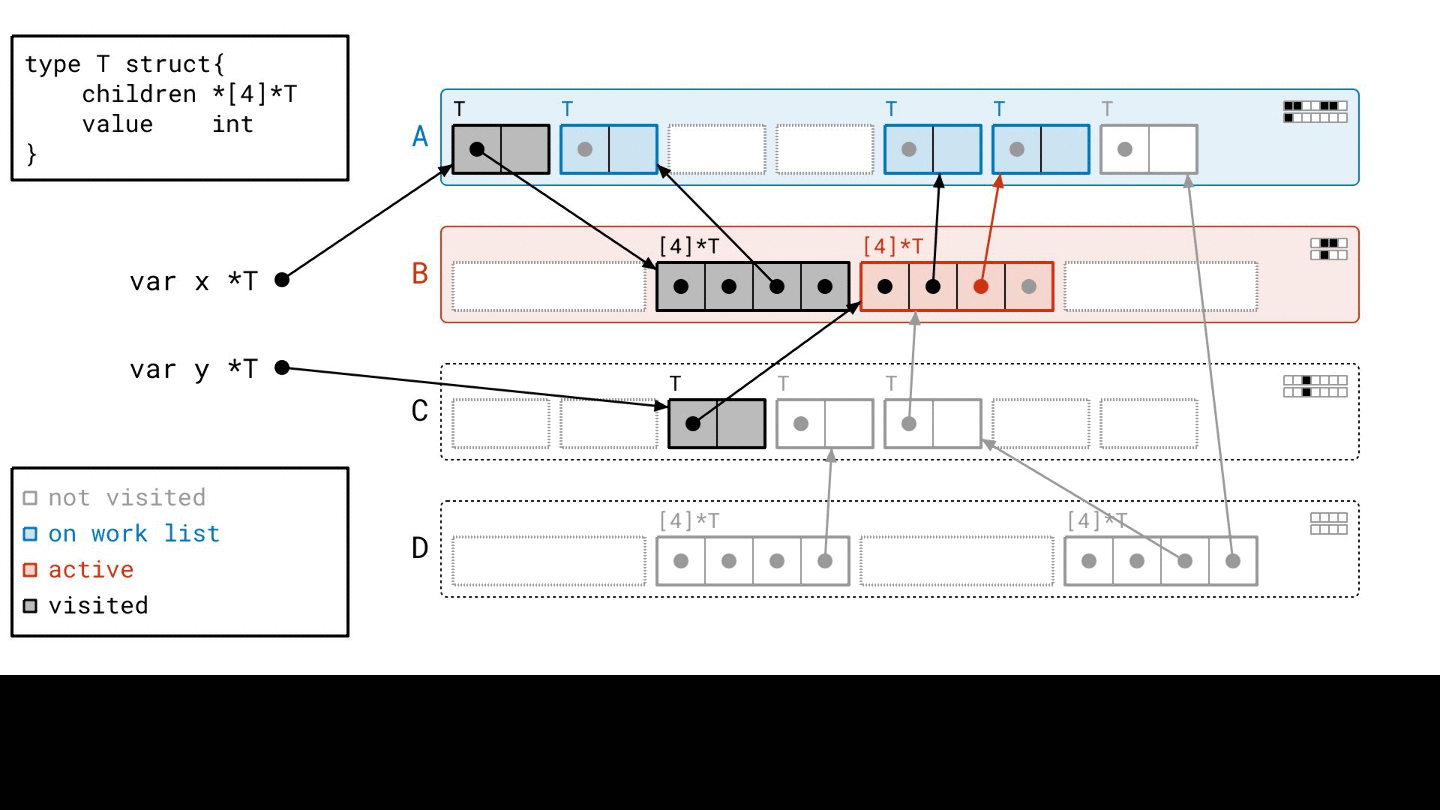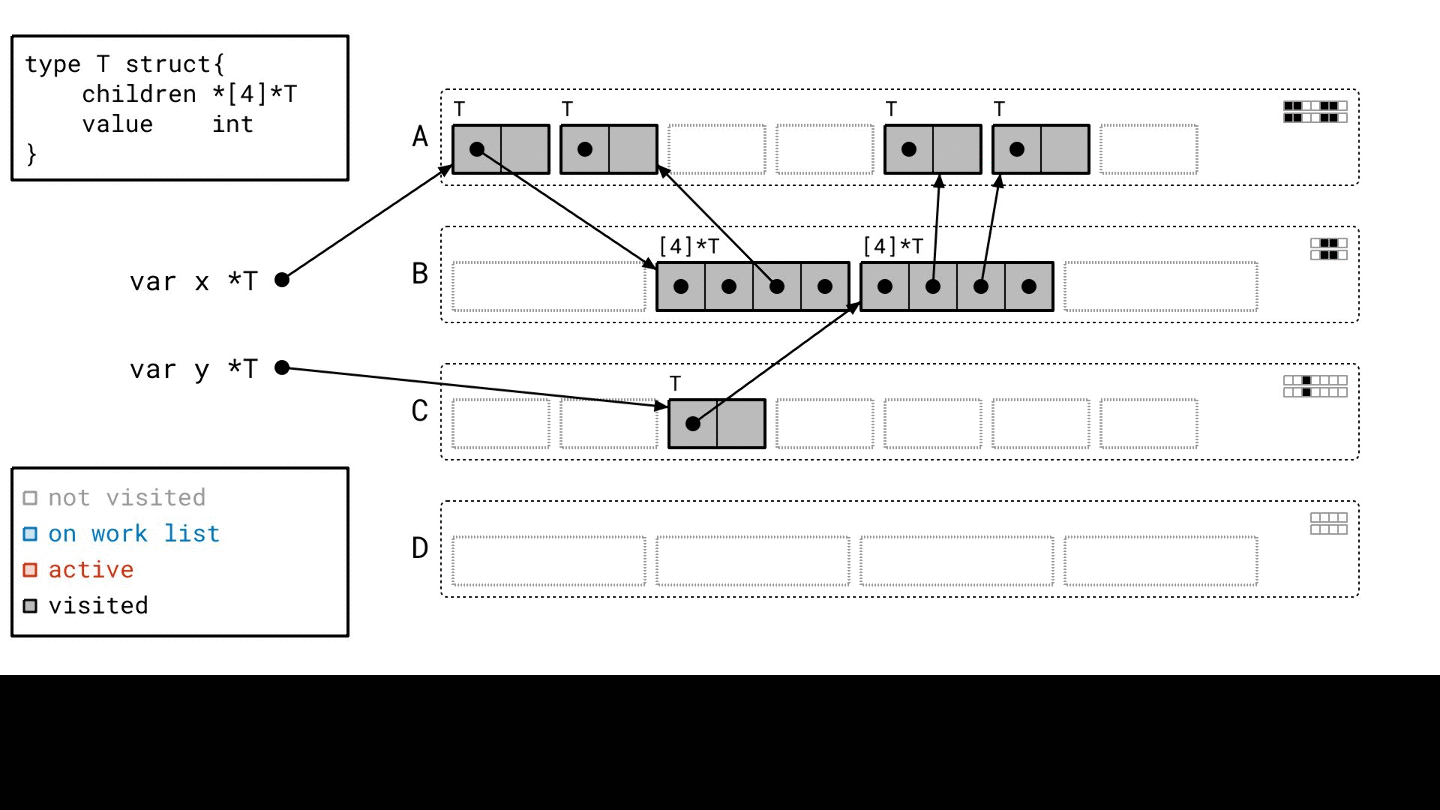
改成掃描 page 的方式會減少 scan 的次數,不過每一次 scan 的時間會變長
但這也是沒關係的,因為每一個 page 裡面的 object 都是緊密相鄰的,也就是說 cache hit 的機率更高對吧
又因為 scan 的次數減少了,也代表 CPU 的壓力會降低
| Flood | Green Tea |
|---|---|
 |
 |
| ref: The Green Tea Garbage Collector | ref: The Green Tea Garbage Collector |
並且 Green Tea 可以受益於 CPU 架構的改進,例如 AVX-512 指令集擁有 512 位元的暫存器的大小允許 Green Tea 可以將 metadata 全部塞進去,而且在 vector register 上也有 bitwise operation 的支援,使得 Scanning 的過程僅需少量 CPU cycle 即可完成
Performance Evaluation
根據 Google 官方的測試,Green Tea 普遍情況下可以有 10% ~ 40% 左右的性能提升
不過在某些特定的情況下不是
Green Tea 的做法本質上是將瑣碎的 scan 的次數減少,合併成一個大型的 page scan 來達到加速的效果
問題是,並非每一次都可以這樣 scan
如果遇到 single object per page 的情況,那麼那些優勢就會蕩然無存
注意到,極端情況下,performance 甚至可能會比 Flood 還要差
雖然說實作上有針對 single object per page 的情況做優化,但並沒辦法完全消除
不過,你可能很難遇到這種情況,事實上,只要你能夠掃描 2% 的 page 資料,其效能就能夠超越 Flood 算法
Goroutine Count to Affect Garbage Collection
本次實驗,使用環境如下
1
2
3
4
5
$ uname -a
Linux station 6.8.0-90-generic #91~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Thu Nov 20 15:20:45 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
$ go version
go version go1.25.5 linux/amd64
實驗內容會開到 100000 個 Goroutine 一起測試
其內容就是單純的 time.Sleep 這樣

先查看,不同數量的 Goroutine 開起來的時候,會需要多少的 Heap 以及 Stack 的空間
可以看到,10w 個 Goroutine 會使用到約 200MB 的 Stack 記憶體
可以得出一個 Goroutine 會先分配 2KB 的空間,跟官方宣稱的一樣
Heap 記憶體的部份,10w 個 Goroutine 則是大概 56MB 左右


而實際測試出來的 GC 時間,也可以看到,基本上 Green Tea 的 GC 時間是比 Flood 要來的短
只不過正如前面提到的,性能提昇的幅度並不是很大
實際跑測試大概落在 14% 左右
關於 benchmark 的實作可以參考 ambersun1234/blog-labs/golang-gc
Leave a comment