資料庫 - Autovacuum 在 PostgreSQL 中的重要性
MVCC(Multi-Version Concurrency Control)
為了盡量避免每次讀取資料庫的時候都要進行上鎖
MVCC 的機制被提出來,它主要允許每一筆 SQL statement 都能夠看到固定的快照
其他人的操作對你來說是不可見的
也就是說其實每個版本的操作都有被記錄下來
MVCC 的出現,使得 “讀取不會擋住寫入,而寫入也不會擋住讀取” 成為可能
你能夠盡量的避免使用 lock 的情況發生,進而提昇系統的併發能力
注意到,MVCC 並不能保證應用程式層級資料的正確性,所以 Transaction 的機制還是必要的
有關 Transaction 的介紹,可以參考 資料庫 - Transaction 與 Isolation | Shawn Hsu
Data Preserving
要能夠看到任意時候的快照,意味著資料必須進行保留
也就是說 DELETE 操作不能真的刪除資料,而是要進行標記
UPDATE 操作不能真的更新資料,而是要寫入一筆新的資料,並將舊的資料做標記
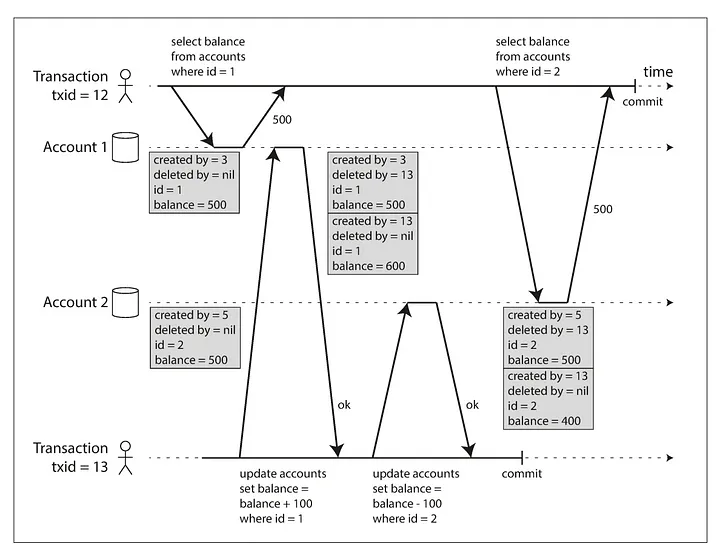
就像上圖所示,id = 1 的資料同時有多個版本
這就是 MVCC 能夠正確運作的基礎
Heap-Only Tuples(HOT)
Data Preserving 的機制會導致資料的儲存成本增加
但不僅僅是儲存的空間變多,其實效能也會變差
因為刪除舊的資料,很明顯,不只資料本身需要更新
舉例來說你需要
- 新的資料 index 建立
- 舊的資料 index 刪除
等等的,這些操作帶來的 overhead 是非常可觀的(i.e. index bloat)
而 PostgreSQL 引入了所謂的 Heap-Only Tuples(HOT) 來解決
癥結點就是更新資料的時候需要同時更新 index 而產生的 overhead
他們的想法是這樣子,我用一個重新導向將新舊資料連接起來
如此一來,便省去了上述 index 更新的 overhead
但這有兩個大前提
- index 上的資料需要一模一樣才能接起來
- FreeSpace 上還有空間可以塞
專有名詞如
ItemIdData,Item以及t_ctid可參考 PostgreSQL Page
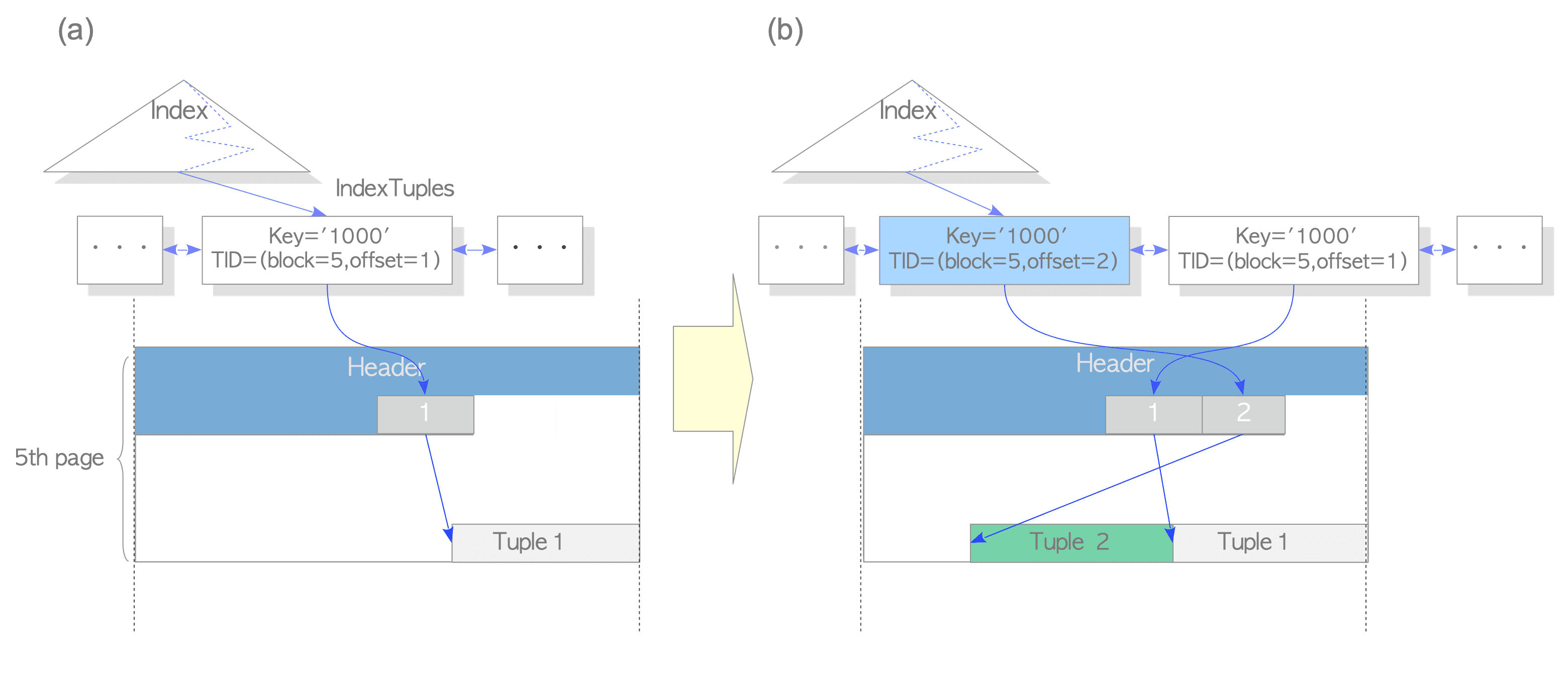
沒有 Heap-Only Tuples(HOT) 的時候
狀況就如上圖一樣,跟我們認知的相同,因為 MVCC 的架構,更新實際上是 INSERT + DELETE
所以會有兩個版本(2 個 Item, 2 個 ItemIdData 以及 2 個 index)
ItemIdData 分別指向個別的版本資料
在 index 資料相同的情況下,它會指向最新的資料,而你不需要新增額外的一筆 index
你存取的 index 仍然會是相同的(注意到上圖有兩個 index,而 HOT 只有一個)
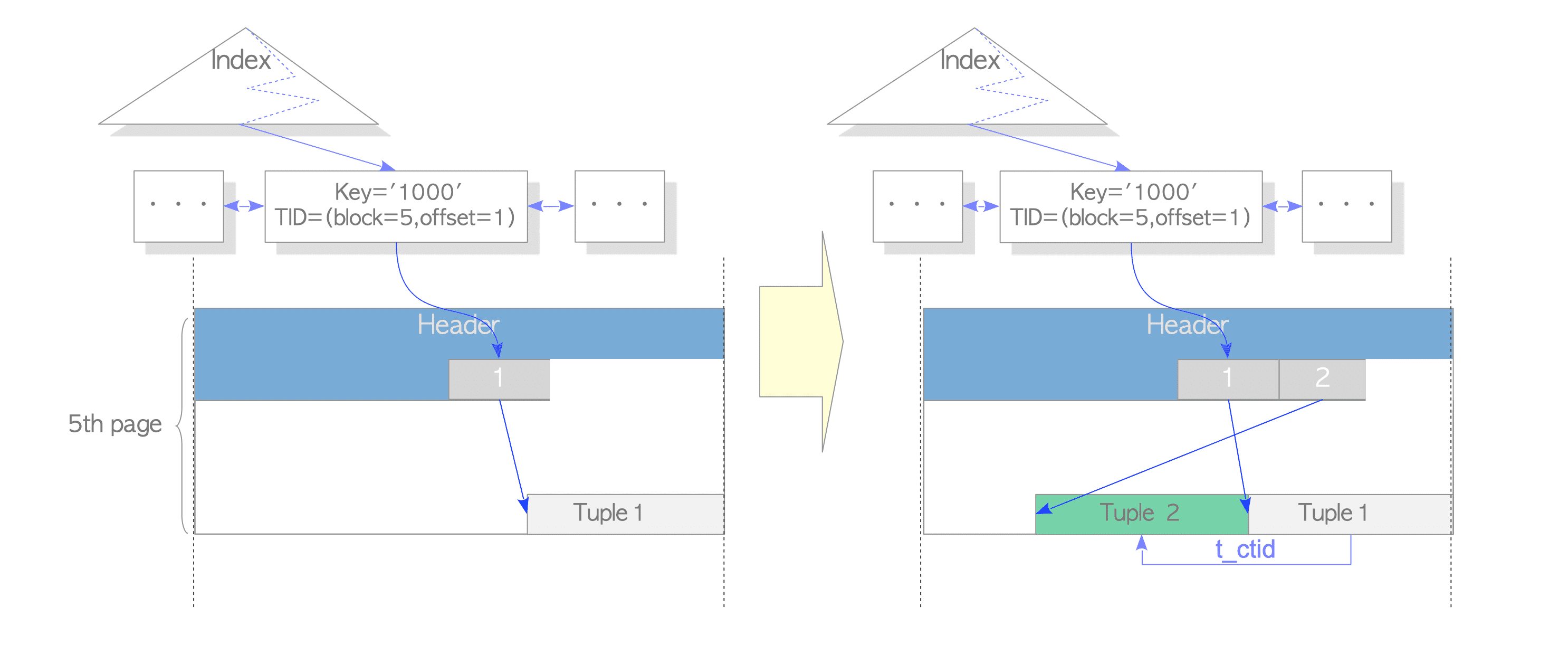
有了 Heap-Only Tuples(HOT) 之後
其實是分兩個步驟來完成
第一步會先透過 t_ctid(可參考 PostgreSQL Page) 將 tuple 重定向到最新的資料
等到舊的資料已經沒有需要被存取之後
就能夠在舊的 ItemIdData 裡面指向新的 Item 的 ItemIdData
PostgreSQL 稱之為 Pruning
最終就會如下圖
Pruning 除了在 AutoVacuum 會自己跑,當你在進行
SELECT操作的時候也會自己跑
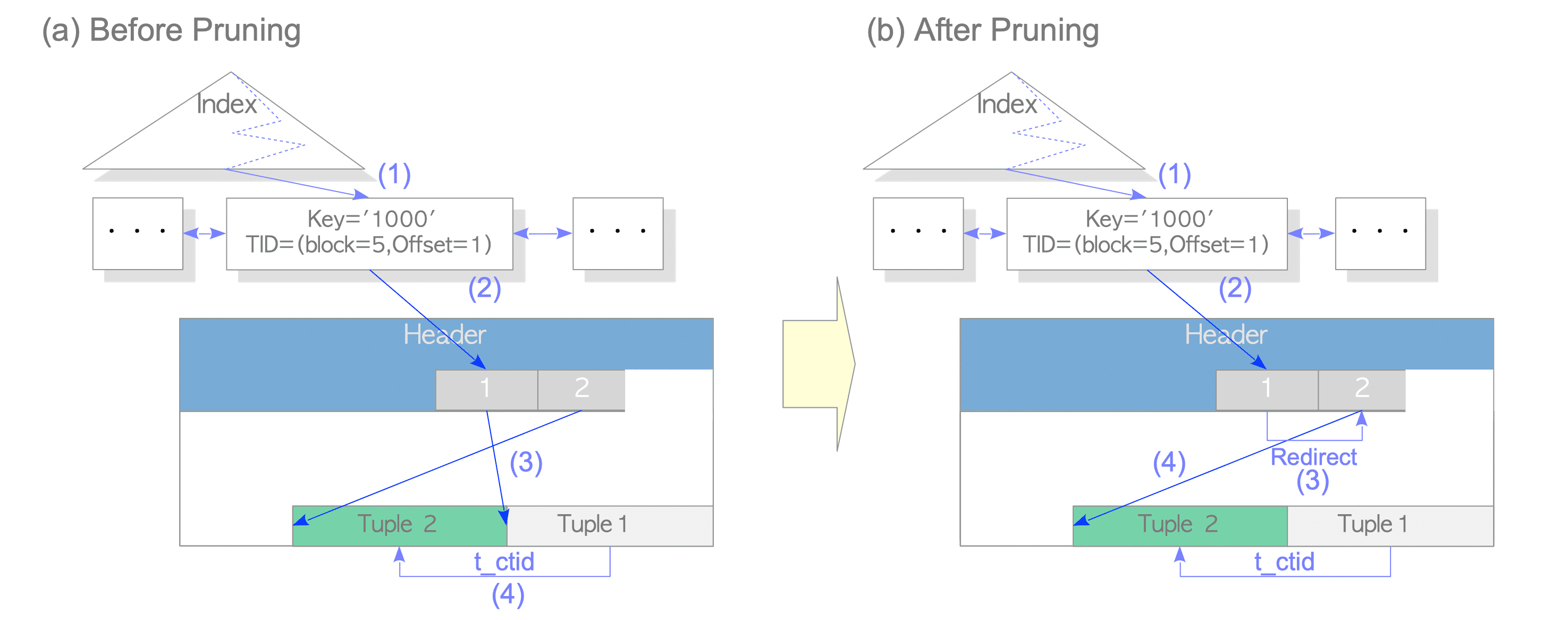
你可能會有疑問,為什麼一開始不直接改 ItemIdData? 而是要先改 t_ctid?
原因在於 MVCC 的架構
舊的資料可能還正在被其他人使用,如果直接把門牌改掉,舊資料就找不到了
所以這其實是一種保護機制
Indexes always refer to the page item identifier of the original row version.
可參考 PostgreSQL Page
Table Bloat
可是資料的保留終究有個上限,不然你的資料庫裡面會塞滿陳舊的資料
最終導致被塞爆然後效能降低
這很明顯不是我們希望看到的,因此需要進行清理
這部份是透過 Vacuuming 來完成
PostgreSQL Page
PostgreSQL 的 table 以及 index 都是以 page 為單位進行儲存的
內部的結構就只是單純的 array of pages
一個 page 的大小通常為
8KB
對於 table 來說,每個 page 都是一樣的
不過對於 index 來說,第一個 page 通常是 reserved page,用於保存 metapage holding control information
Page Layout

一個 page 主要由以下構成
Header: 該 page 的各種控制資訊,比如說 free space 的起點與終點ItemIdData: 該 item 的詳細資訊,包含怎麼解析該 item 的資料FreeSpaceItems: 真正儲存資料的地方,需要透過ItemIdData裡面的控制 bits 來解析SpecialSpace: 用於儲存特殊資料
因為 page 是 PostgreSQL 的儲存單位,它需要兼容各種不同類型的 table,所以
ItemIdData裡面需要保存控制 bits 來決定要怎麼解析該 item 的資料
比如說 HeapTupleHeaderData
ItemIdData 從 FreeSpace 的 起點 往後 allocate
而 Items 則是從 FreeSpace 的 終點 往後 allocate
而這個起終點的位置可以從 page header 中取得
HeapTupleHeaderData
儲存資料用的資料結構就是 HeapTupleHeaderData
其中比較值得注意的是 t_xmin 與 t_xmax 這兩個欄位
他們分別代表 Insert 以及 Delete 的 Transaction ID
這些 Id 就是拿來計算快照用的資料
假設目前的 XID 是 100
然後該 tuple 的 t_xmin 是 90,t_xmax 是 0
這代表目前你看得到這筆資料,因為目前的 XID 已經超過 t_xmin 的值
而 t_xmax 是 0 則代表這筆資料沒有被刪除過
也就是說該筆 tuple 是 live 的
只有當它被刪除的時候 t_xmax 才會被設置為非 0 的值
另外 t_ctid 是一個指向該 tuple 所在 page 的指標
在 Heap-Only Tuples(HOT) 中使用到的方法底層是依賴這個欄位來進行重定向的
所以官網的說明才會是
current TID of this or newer row version
最後,一個 page 通常會儲存一些額外的資訊,它通常是用 flag bits 來表示
這些資訊是儲存在 t_infomask 以及 t_infomask2 這兩個欄位中
PostgreSQL Vacuuming
這種需要定時進行 維護 的行為,稱之為 Vacuuming
它做的事情可不只是清理資料,總的來說有以下幾個
Recover Disk Space
就是要清理我們在 Table Bloat 中提到的資料
這些舊的資料,稱為 Dead Tuple(i.e. Dead Row)
如果某個版本的資料都已經被處理完了,沒有任何 Transaction 有機會看到它,那是不是就能夠被刪除了呢?
所以就可以直接刪除它,回收空間
注意到這裡的回收空間並不是放回去給 OS
但有特例,如果可回收的空間是在整張 table 的最尾端,那的確就可以放回去給 OS
Statistics Collection
把資料刪了,底下的統計資料也要進行更新
意思是說,我們知道你在下 SQL 的時候,資料庫系統會幫你做各種的優化
比如說要不要使用 index,要不要做 full table scan 等等的
你可以使用
EXPLAIN指令來查看資料庫系統的決策
這些決策會需要使用 統計資料 來決定
隨著不斷使用,INSERT, UPDATE, DELETE 皆會對這些統計資料造成影響
不過頻率高的更新並不一定能夠給統計資料提供有用的資訊
常見的判斷可以是該欄位的 最大最小值
ANALYZE 指令就是用來更新統計資料的
它會對全部的 table 以及 materialized view 進行統計
所有統計過後的資料會儲存於 pg_statistic 這個 table 中
注意到,子表的更新並不會觸發父表的統計資料更新
Visibility Map
如果 Recover Disk Space 都要走訪每個 row 去看他是不是 Dead Tuple 那一定會很累
我們知道,資料實際上是儲存在 page 中的(可參考 PostgreSQL Page),那這邊就是一個加速點了
如果 page 裡面所有的資料都是乾淨的,那麼 vacuum 是不是就不用看這頁了
也就可以加速 vacuum 的過程
紀錄 page 的乾淨與否,這些資料每個 page 總共只有佔 2 bits
All-Visible: page 的每個 tuple(i.e. row) 都沒有需要被清理(沒有 Dead Tuple)All-Frozen: page 的每個 tuple 都被 frozen(可參考 Transaction ID Wraparound)
以上兩個資料構成所謂的 Visibility Map(VM)
Visibility Map 的名字通常帶有 _vm 後綴
而主要的名字會是跟隨 filenode number
也就是說,假設 filenode number 為 123456,那麼 VM 的名字就會是 123456_vm
Speed up Index-Only Scan
All-Visible 表示該 page 的每個 tuple 都被視為是 “可見” 的,沒有 Dead Tuple 需要被清理
這在一定程度上可以加速 index-only scan
有關 index 可以參考 資料庫 - Index 與 Histogram 篇 | Shawn Hsu
稍微複習一下
如果你的 query 要撈的資料全部都在 index 上面,並且 query 本身也都有正確的使用到 index
那麼 look up 只需要在 index table 上面做就可以了
反之,就需要兩次的 table look up(index 表 + data 表)
MVCC(Multi-Version Concurrency Control) 這件事情讓查詢變得比較複雜
你必須要確認說 index table 上面的資料是可見的,而 index table 上面並不會紀錄,正常情況下你需要進去主表查詢才可以
那使用 Visibility Map 就可以加速這個過程
如果你要找的資料,它所屬的 page,Visibility Map 是 All-Visible,那麼你就可以確定說東西是對所有 Transaction 可見的
因此你不必特地跑過去主表查詢
也因為 Visibility Map 非常的小,它通常座落於記憶體內部,相比主表查詢,整體的 I/O 成本會更低
Transaction ID Wraparound
PostgreSQL 的 Transaction 是基於 Transaction ID(i.e. XID) 來進行管理的
如果 A row 的 XID > B row 的 XID,那麼 A row 的資料時間一定是比較新的
PostgreSQL 內的 XID 大小是 32 bits,也就是大約 4 billion 個 Transaction 的數量
因為 XID 有大小限制,所以毫無疑問它一定會有用完的一天
當數字用完,XID 會從 0 開始重新計算,那這樣子來說,XID 1 會比 XID 0 還要新(可是他是錯誤的)
這個問題被稱為 Transaction ID Wraparound
為了處理這種情況,針對太久的 tuple,PostgreSQL 會將其 Freeze
具體的作法是將 XID 指定為一個常數 FrozenTransactionId,當你碰到這個數字的時候,它就代表這個 tuple 是非常久以前的資料
並且不受限於 XID 的比大小限制
另外 XID 的計算會是循環的,他是將 40 億的空間切成兩半
前 20 億是比當前新的,後 20 億是比當前舊的
Frozen tuple 或 Frozen page 並不代表看不見,它只是為了要區分上古時期的資料而已
這樣做的好處,在 Visibility Map 中的作用就只是加速 Vacuum 的過程
不過究竟哪時候,一個 tuple(i.e. row) 會被 freeze 呢?
使用 vacuum_freeze_min_age 可以指定說,當 tuple 的 age 大於這個值的時候,就將它 freeze
我們說的 age 就是 tuple 已經存在多少次的交易
該 tuple 的 XID 值 - 當前 XID 值 = age
所以一個 page 的狀態通常是同時包含 live-tuple 以及 frozen-tuple 的
這種狀態,它既不是 All-Visible 也不是 All-Frozen
換句話說,在這種狀況下,Visibility Map 兩個都是 0,導致說 Vacuum 每次都需要走訪這些 page
這樣對加速的幫助就沒那麼大了
Vacuum 能看越少的 page 對他的效能會越好
所以他的目標是盡量減少需要拜訪的 page 數量
混合狀態的沒辦法略過,還是必須走訪,那如果是 All-Visible 的話呢?
一般情況下,All-Visible 與 All-Frozen 都可以跳過不看(符合 Visibility Map 中我們討論的)
但是 All-Visible 一直把它放著最終它會變老,一直佔用著 XID 最終會導致 Transaction ID Wraparound 的發生
為了避免它發生,Vacuum 會變成較為激進的方式(i.e. Eager Vacuum),它會想辦法將它全部轉換為 All-Frozen,如此一來 page 的數量減少
Vacuum 就能夠執行的更快速
Frozen 的 tuple 可以回到 live 的狀態,當你更新 tuple 的時候,page 的狀態就不在是
All-Frozen
所以如果你的 vacuum_freeze_min_age 調整的太小,然後 tuple 又常常更新,這最終會導致無用功
How to do Vacuuming
VACUUM 指令就是用來進行 Vacuuming 的
在執行的時候,它並不會 block 其他一般操作(i.e. SELECT, INSERT, UPDATE, DELETE, 但是像 ALTER TABLE 這種操作,它會 block 住)
並且因為它實際上是在做底層 I/O 操作,所以會在一定程度上影響到其他 active session 的效能
另一種 VACUUM FULL 指令則有辦法回收更多空間,不過它執行的速度也更加的慢
並且它會鎖住整張 table,直到執行完成
因此,在一般情況下,你都應該優先使用 VACUUM
注意到 vacuum 的目的並不是一直維持最小的資料使用空間,而是嘗試維持平穩的資料使用空間
如果是針對很常更新的資料表,當你在上一個瞬間把它縮到最小,下一個瞬間又變大了,不就做白工?
因此,維持穩定的資料使用空間才是 vacuum 的目標
那要維持穩定的資料使用空間,經常做 VACUUM 反而比 VACUUM FULL 來的好
Autovacuum Daemon
有的人會嘗試自己設定個 cronjob 去執行 VACUUM
但這樣有個缺點是,在固定時間執行,你並不能保證在該時段一定是資料庫的低峰期,萬一不是,那資料量會大到需要執行 VACUUM FULL 才能完成
這與你當初的設想天差地遠,甚至還會更糟
Autovacuum Daemon 就是一個可以自動執行 VACUUM 與 ANALYZE 的服務
它厲害的地方在於他是動態執行的,它並不是根據固定時間執行
而是根據更新的頻率來決定的,並且由於我們提到的 vacuum 的目的,因此 Autovacuum Daemon 只會執行 VACUUM 而不會執行 VACUUM FULL
Autovacuum Worker
Autovacuum Daemon 會啟動多個 worker 來執行 vacuuming 的工作
每個 worker 工作的單位是 per table 的,當有多個 table 需要被清理的時候,worker 就會一個一個解決,如果目前沒有 worker 有空,它就必須等待
前面我們提到 Autovacuum Daemon 會根據更新的頻率來決定觸發頻率
但具體來說到底是怎麼個決定法呢?
有三種時間點
- 當 table 的
relfrozenxid超過 autovacuum_freeze_max_age 的值 - 當距離上一次 Vacuum,table 的
Dead Tuple數量超過 vacuum threshold - 當距離上一次 Vacuum,table 寫入的 Tuple 數量超過 vacuum insert threshold
基本上都是為了解決我們上述討論到的問題
- 這是避免 Transaction ID Wraparound 的發生
Dead Tuple數量過多會造成 Table Bloat 的發生- 寫入數量過多,會急速增長資料,導致 Transaction ID Wraparound 提早發生。因此當寫入遠超預期,如果能提早進行 Vacuum 將資料 Frozen,將壓力分散到日常運作而非一次性清理,會是比較好的作法
Worker 一般而言並不會 Block 其他操作,如果真的有衝突,通常 Autovacuum Daemon 會退讓
因為服務本身是比較重要的,但是如果是遇到 Transaction ID Wraparound 的問題,很明顯這個問題比較重要因為它會導致整個資料庫系統癱瘓
在這種情況下,Worker 並不會退讓
Experiment
Setup
1
2
3
4
5
6
7
8
$ uname -a
Linux station 6.8.0-101-generic #101~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Wed Feb 11 13:19:54 UTC x86_64 x86_64 x86_64 GNU/Linux
$ docker --version
Docker version 29.2.1, build a5c7197
> SELECT version();
PostgreSQL 15.4 (Debian 15.4-1.pgdg120+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit
1
2
3
4
5
6
7
8
$ docker run --name pg-experiment \
-e POSTGRES_PASSWORD=postgres \
-e POSTGRES_USER=postgres \
-e POSTGRES_DB=postgres \
-p 5432:5432 \
-d postgres \
-c 'shared_preload_libraries=pg_stat_statements' \
-c 'autovacuum=off'
Enable PostgreSQL Extensions
1
2
CREATE EXTENSION IF NOT EXISTS pageinspect;
CREATE EXTENSION IF NOT EXISTS pg_visibility;
MVCC(Multi-Version Concurrency Control)
我們一直提到說 update = insert + delete,那就來驗證一下
1
2
CREATE TABLE mvcc(id int PRIMARY KEY, val text);
INSERT INTO mvcc VALUES (1, 'A');
然後觀察資料寫入之後的狀態
1
SELECT * FROM heap_page_items(get_raw_page('mvcc', 0));
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"lp": 1,
"lp_off": 8160,
"lp_flags": 1,
"lp_len": 30,
"t_xmin": "729",
"t_xmax": "0",
"t_field3": 0,
"t_ctid": "(0,1)",
"t_infomask2": 2,
"t_infomask": 2050,
"t_hoff": 24,
"t_bits": null,
"t_oid": null,
"t_data": {
"0": 1, "1": 0, "2": 0, "3": 0, "4": 5, "5": 65
}
}
更新資料之後再次觀察
1
2
UPDATE mvcc SET val = 'B' WHERE id = 1;
SELECT * FROM heap_page_items(get_raw_page('mvcc', 0));
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
{
"lp": 1,
"lp_off": 8160,
"lp_flags": 1,
"lp_len": 30,
"t_xmin": "729",
"t_xmax": "730",
"t_field3": 0,
"t_ctid": "(0,2)",
"t_infomask2": 16386,
"t_infomask": 258,
"t_hoff": 24,
"t_bits": null,
"t_oid": null,
"t_data": { "0": 1, "1": 0, "2": 0, "3": 0, "4": 5, "5": 65 }
},
{
"lp": 2,
"lp_off": 8128,
"lp_flags": 1,
"lp_len": 30,
"t_xmin": "730",
"t_xmax": "0",
"t_field3": 0,
"t_ctid": "(0,2)",
"t_infomask2": 32770,
"t_infomask": 10242,
"t_hoff": 24,
"t_bits": null,
"t_oid": null,
"t_data": { "0": 1, "1": 0, "2": 0, "3": 0, "4": 5, "5": 66 }
}
你可以發現舊資料(i.e. lp1) 的 t_xmax 已經不是 0 了,表示說它已經被標記為被刪除的了
而 lp2 的 t_xmax 為 0,表示他是目前最新的資料
lp1 的
t_xmax為730,同一時間也等於 lp2 的t_xmin,表示說 lp2 是 lp1 的更新版本
這也直接證明說,在 PostgreSQL 中,update = insert + delete 是真的
HOT(Heap-Only Tuple)
而上述的例子 MVCC(Multi-Version Concurrency Control) 中,你也可以看到 lp1 的 t_ctid 指向 (0,2) 也就是新的資料(i.e. lp2)
換句話說,同時它也是 HOT 的資料
我們可以透過 t_infomask2 這個欄位的資訊來解析
lp2 的 t_infomask2 為 32770,搭配 flag bits 的定義,我們可以知道他是屬於 32768 + 2
他是屬於 HEAP_ONLY_TUPLE 與 HEAP_NATTS_MASK 的組合
原本 lp1 的 t_infomask2 為 16386,搭配 flag bits 的定義,我們可以知道他是屬於 16384 + 2
他是屬於 HEAP_HOT_UPDATED 與 HEAP_NATTS_MASK 的組合
這個 +2 是 number of attributes
也正好對應到實驗本身只有 2 個欄位
src/include/access/htup_details.h#L187C1-L197C75
1
2
3
4
5
6
7
8
9
10
11
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID_OLD 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo CID */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
src/include/access/htup_details.h#L288C1-L298C63
1
2
3
4
5
6
7
8
9
10
11
/*
* information stored in t_infomask2:
*/
#define HEAP_NATTS_MASK 0x07FF /* 11 bits for number of attributes */
/* bits 0x1800 are available */
#define HEAP_KEYS_UPDATED 0x2000 /* tuple was updated and key cols
* modified, or tuple deleted */
#define HEAP_HOT_UPDATED 0x4000 /* tuple was HOT-updated */
#define HEAP_ONLY_TUPLE 0x8000 /* this is heap-only tuple */
#define HEAP2_XACT_MASK 0xE000 /* visibility-related bits */
可是如你所見,兩筆資料的 lp_flags 都是 1,但是它應該要在 ItemIdData 中直接做 redirect 才對
事實上這是因為我們把 Autovacuum 關閉了
當你執行 VACUUM 之後就會正確導向
再次觀察資料
1
SELECT * FROM heap_page_items(get_raw_page('mvcc', 0));
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
{
"lp": 1,
"lp_off": 2,
"lp_flags": 2,
"lp_len": 0,
"t_xmin": null,
"t_xmax": null,
"t_field3": null,
"t_ctid": null,
"t_infomask2": null,
"t_infomask": null,
"t_hoff": null,
"t_bits": null,
"t_oid": null,
"t_data": null
},
{
"lp": 2,
"lp_off": 8160,
"lp_flags": 1,
"lp_len": 30,
"t_xmin": "730",
"t_xmax": "0",
"t_field3": 0,
"t_ctid": "(0,2)",
"t_infomask2": 32770,
"t_infomask": 10498,
"t_hoff": 24,
"t_bits": null,
"t_oid": null,
"t_data": {
"0": 1, "1": 0, "2": 0, "3": 0, "4": 5, "5": 66
}
}
你可以看到 lp1 的資料都被清空,並且他的 lp_flags 變成 2 且 lp_off 也變成 2
這就對應到說 Pruning 的機制已經完成
src/include/storage/itemid.h#L34C1-L41C61
1
2
3
4
5
6
7
8
/*
* lp_flags has these possible states. An UNUSED line pointer is available
* for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* unused (should always have lp_len=0) */
#define LP_NORMAL 1 /* used (should always have lp_len>0) */
#define LP_REDIRECT 2 /* HOT redirect (should have lp_len=0) */
#define LP_DEAD 3 /* dead, may or may not have storage */
根據 lp_flags 的定義,2 代表 LP_REDIRECT
然後 lp_off 表示 offset 到新的資料,指向 目標 Item Number (lp 序號)
以這個例子來說,就是下一個
Leave a comment