資料庫 - 機率型資料結構 Bloom Filter 在 Cache 中的應用
Cache Issues
就像我們在 資料庫 - Cache Strategies 與常見的 Solutions | Shawn Hsu 當中提到的
如果碰到惡意攻擊,查詢不在 cache 也不在 database 裡面的資料,那麼所有的請求都會直接到 database,然後又會直接被打爆
所以其實在這種狀況底下,直接讓請求到 database 是不好的選項
當然除了你對它設計 rate limit,阻擋某個 IP 過來的請求
可是這樣也不是一個太好的選項,雖然會動
是不是用一個可以快速查詢的方式,就可以將所有不在 cache 也不在 database 裡面的請求,直接快速返回呢?
顯而易見的,使用 Hash Function 來實作是一個很好的選項
Probabilistic Data Structure
這種要求就會需要用到機率型資料結構
這些資料結構能夠提供 “概略的” 統計資料,比方說
- 這個資料存不存在
- 某某資料的數量是多少
等等的
相比於傳統的資料結構,雖然能夠統計出最完整的資料,不過效率上會慢非常多
這也是為什麼機率型資料結構受到歡迎的原因,犧牲一點的準確性,換取極高的效率
Hash Function
要怎麼快速的,比如說查詢資料存不存在
最直覺的作法肯定是將資料本身做個 hash
查詢的時候,就做一樣過 hash function 得出結果,然後看看有沒有這個資料就可以了
所以其實機率型資料結構的實作,就是依靠 hash function 來達成的
Why not Hash Table only?
碰撞問題在算 hash 的時候是很常會遇到的問題
以下的實作方法雖然本質上都是使用 Hash Function 來實作
但是為什麼不單純只算一次,而是比如說
- Bloom Filter: 採用 多次 hash 的作法
- Cuckoo Filter: 採用 雙 hash 的作法
等多次的算法,目的為何?
其實說白了就是要降低碰撞的概率,降低誤判的機率
機率型結構同時滿足,”空間換時間” 以及 “準確率換時間” 的特性
所以單純的一次 hash 實務上是不太會使用的
Different Types of Probabilistic Data Structure
| Probabilistic Data Structure | Insertion | Query | Deletion | Modification | Space Utilization |
|---|---|---|---|---|---|
| Bloom Filter | $O(K)$ | $O(K)$ | Very Low | ||
| Scalable(Stackable) Bloom Filter | $O(K)$ | $O(K * L)$ | Low | ||
| Cuckoo Filter | $O(1)$ | $O(1)$ | Medium | ||
| XOR Filter | $O(1)$ | $O(1)$ | High | ||
| Binary Fuse Filter | $O(1)$ | $O(1)$ | Very High |
每筆資料所需空間: Bloom Filter > Scalable(Stackable) Bloom Filter > Cuckoo Filter > XOR Filter > Binary Fuse Filter
Bloom Filter
Bloom Filter 是一種機率型資料結構,可以快速判斷資料是否存在
當資料不存在時,可以快速返回結果,避免無謂的查詢
基本的概念是,透過一個巨大的 bit array,將同一筆資料做 多次 hash,然後將結果存到 array 裡面
以下圖來說就是三次 hash

ref: Bloom Filter
假設你做了三次 hash,那麼 hash 出來的結果會被寫入三個不同的位置,不是 0 就是 1
那他要怎麼做查詢呢?
將輸入也做同樣的三次 hash,如果相對位置上的資料都是 1,那這筆資料 “應該” 是存在的
為什麼是應該呢?
因為,hash function 會有碰撞的問題嘛
有可能不同的輸入,hash 出來的結果是相同的
而採用 多次 hash 的作法,可以降低碰撞的機率
但並不是完全可以避免
只有算出來的東西 全部都是 1,那這筆資料可能是存在的(i.e. false positive,因為同一個位置有可能有其他資料 map 到這裡)
那如果有一個位置是 0,那這筆資料就絕對不存在(比如說上圖的 w)
那會不會有一種狀況是,Bloom Filter 的資料滿了呢?
會的吧? 那到時候是不是整條 bit array 的內容都幾乎是 1 了呢?
在這樣的情況下,Bloom Filter 的準確性就會下降,就是你丟啥進去它都是 true 了
那能不能考慮將資料刪除呢? 不行,因為有可能同一個位置有多筆資料 map 到同一個位置
強制把它清 0 會讓其他原本準確的資料也一起被清掉
所以 Bloom Filter 不支援刪除
Better Bloom Filter
不過,多次 hash 實務上也是有缺點的,就是慢
所以 Building a Better Bloom Filter 這篇論文提出了一些改進的方式
簡單講就是透過計算兩次的 hash 結果之後,利用以上結果把剩下的全部推論出來
1
2
3
4
5
bit_vector[hash1] = 1
bit_vector[hash2] = 1
for i in range(0, k-1):
bit_vector[hash1 + i * hash2] = 1
而這牽扯到一個數學問題,如果你的 bit_vector 的長度與 hash2 的結果有公因數
那你可能會很快的將 Bloom Filter 全部塞滿
就是說,假設陣列大小是 10
hash2 的結果是 2
那你之後步進的結果就是 2, 4, 6, 8, 0, 2, 4, 6, 8, ...
等於說你有很大的機率會重複,這樣誤判率上升,對吧
與其去限制 hash2 不如控制陣列的大小
既然重點是 互質,將陣列大小設定為質數不就好了?
這也是為什麼工程上通常會設定 100003 而不是 100000
Scalable(Stackable) Bloom Filter
Bloom Filter 是沒辦法做刪除的,而且也沒有辦法擴展
也就是說,在一開始的時候 bit array 的大小就要事先決定好
但是這樣就不好用了阿? 所以一個變種 Scalable Bloom Filter 就出現了
既然一個 Filter 不夠,那就再加一個
而新增的這一層通常會比原本的大一倍,為了不夠然後又繼續加層數
這樣下去,查詢的時間除了原本的 hash 次數,還要再加上層數(L)
所以是 $O(K \times L)$
寫入的部份因為只需要寫入最新的那一層(因為舊的那層滿了嘛),所以是 $O(K)$
如果我重複寫入相同的資料呢?
會需要先檢查,確定不存在再寫嗎?
實務上通常不這樣做,因為新的層數會是先前的一倍大,多幾個 bit 的資料影響不大
而且先查再寫會大幅度的增加 overhead(因為查詢是 $O(K \times L)$)
Cuckoo Filter
Cuckoo Filter 不同於 Bloom Filter,它採用 雙 hash 的作法,計算出資料的 fingerprint
然後在相對應的位置上標記
而這種作法,也會出現 false positive 的問題(i.e. 相同 fingerprint)
計算 fingerprint 的好處在於,能夠做到 刪除的功能
因為我儲存的是資料的 fingerprint,而不是資料模糊之後的結果(Bloom Filter 儲存的是去特徵化後的結果映射)
我能夠定位到唯一的資料,然後刪除它
不過,hash 的原罪就是會碰撞,有沒有可能 fingerprint 也相同呢?
所以對於刪除 你只能刪除某個,你確定有加入過的資料
那我有多個加入過的資料,然後 fingerprint 也相同呢?
這就要講回到 雙 hash 的作法了(i.e. cuckoo hashing)
兩種 hash function 分別長這樣
- $h_1(x) = \text{hash}(x)$
- $h_2(x) = h_1(x) \oplus \text{hash}(\text{fingerprint}(x))$
fingerprint 也可以讓整個 filter 的 size 變得更緊湊
原因在於判斷存在與否僅須看兩個位置,就算旁邊資料是滿的,也不影響判斷
而 Bloom Filter 資料如果塞太滿,會導致誤判的機率上升(就像課本上畫滿重點,整本都是重點,整本也都不是重點)
由於 $\oplus$(xor) 的特性,你只要知道其中一個 hash 值,你就能夠推導出另一個
那為什麼要算兩個 hash,原因也是要處理碰撞的問題
如果發現 $h_1$ 已經被佔領了,它就會嘗試將資料放到 $h_2$ 的位置上
那如果兩個位置都滿了呢?
cuckoo hashing 的作法會是將舊的資料踢掉,因為你可以算另一個 hash 嘛
所以就一直找下去,如果一直都是滿的就一直踢,直到有空位
當然不太會一直無限找下去啦,所以通常會設定個 threshold,超過就放棄
也就是說 insert 是有可能會失敗的

ref: Cuckoo Hashing
XOR Filter
XOR Filter 的作法則是將儲存的資料變成是 “片段的 fingerprint” 資料
並且只有固定三個片段,然後將這三個片段進行 XOR 運算
得出來的結果,再與 fingerprint 進行比對
如果兩個長的一樣,那這筆資料應該存在
本質也還是算 hash,所以片段的 fingerprint 也會有碰撞的問題
所以 XOR Filter 也會有 false positive 的問題
都是算 fingerprint,why not Cuckoo Filter?
就還是回到 Why not Hash Table only? 的問題
還是空間最大化利用以及準確率換時間的 trade offs
他的出現旨在取代 Bloom Filter,因為以下各種原因
-
XOR Filter 比 Bloom Filter 更快
- 3 + 1 次 hash 比 n 次 hash 快
-
XOR Filter 所需空間比 Bloom Filter 更小
- Bloom Filter 塞太滿,誤判機率會上升
不過他有一個大缺點
要先知道所有儲存資料,你才能開始構件 XOR Filter
因為它本質上是在解方程式,上述的數學式你也看到了
它需要找到 3 個不同的 hash function,使得所有數值填入之後計算出來的等式是成立的
換句話說,XOR Filter 沒辦法 動態新增資料
本質上就是先找到 Degree 1 slot 然後一層一層解析
一個 slot 如果有兩個資料映射到同一個位置,那就不能拆
就是要找到所謂的突破口
很抽象?
\[x + y = 10 \\ y + z = 15 \\ x + z = 11\]單純看 $x + y = 10$ 你可以很簡單的說出答案,可是這個答案他是與其他等式有相依性的
部份解不一定等於全局解
況且它本質上還是 hash function 你更難猜
上述作法稱為
peeling
所以它就沒用了嗎?
其實有些系統是 read heavy 的,將 XOR Filter 應用在此種狀況可以獲得很好的效果
Binary Fuse Filter
你會發現 XOR Filter 的 peeling 過程其實挺容易失敗的
找到共同解沒有這麼簡單,尤其資料量大的時候,萬一失敗它就要重新設定 hash
那既然問題是資料量大的時候,容易失敗
那麼把資料分組不就解決了,所以現在是 分組 也 分片段
- 分組: 將整個 array 切成多個大小相同的小 array 且互不重疊,稱為 segment
- 分片段: 將輸入資料切成 3 個片段(3 次 hash)
而目的是
- 分組: 為了解決 peeling 失敗
- 分片段: 犧牲部份準確率換取時間
如果你不分組,那基本等於 XOR Filter
為了要讓 Binary Fuse Filter 跑得又快又好
其中一個特殊要求是,3 組 hash function 的結果,必須座落於相鄰的 segment 中
也就是說
- 當你算出第一個 hash 結果,找到它應該放在哪個 segment 之後,假設位置
i - 第二個 hash 結果必須放在
i + 1的 segment 中 - 第三個 hash 結果必須放在
i + 2的 segment 中
如果都放在同一個 segment,那就是小號的 XOR Filter
這樣的好處是
- 解決了資料量大可能會出現的 peeling 失敗問題
- 查詢時間更快速,因為 3 次 hash 結果在記憶體中是相鄰的,可以提高 cache hit rate
- peeling 建構過程更順利,只要找到 degree 1 slot 就能夠大幅度提昇找到全局解的機率(因為相鄰,所以找到一個,就可以往後繼續找(燒),所以才叫
fuse)
有關 cache 可以參考 資料庫 - Cache Strategies 與常見的 Solutions | Shawn Hsu
Redis Example
那就來試一下
1
2
$ docker run -itd -p 6379:6379 -p 8001:8001 --name redis redis/redis-stack
$ docker exec -it redis sh
你可以造訪
localhost:8001,這個是 Redis Insight 的 GUI
Bloom Filter
那其實我想試試它撞到會發生什麼事情
所以 Bloom Filter 的錯誤率我會設定成 0.5
然後大小開 10 筆,這樣就比較容易撞到
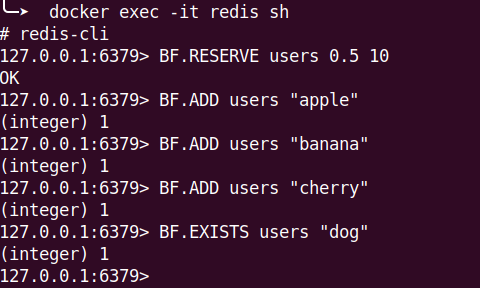
可看到說,我沒有新增 dog 這筆資料,但它卻說存在
這就是 false positive 的問題(當然也是因為我錯誤率設定很高,所以很容易復現)
有關 Bloom Filter 的指令可以參考 BF
Cuckoo Filter
而 Cuckoo Filter 的操作也類似
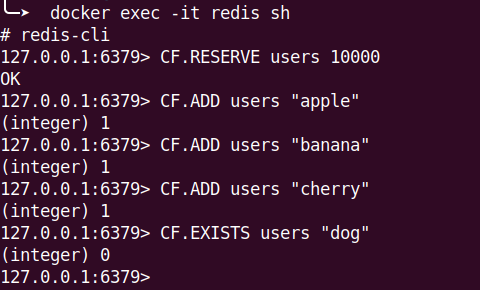
注意到,拿這個範例去跟 Bloom Filter 做比較是沒有意義的
因為他們的錯誤率設定不同,大小也不同,所以不能這樣看
有關 Cuckoo Filter 的指令可以參考 CF
Leave a comment